Mittlerweile ist "Amazon" zum Synonym für Einkäufe jedweger Art geworden. Außer sperrigen Gegenständen vom Baumarkt und Gebrauchtwaren auf Ebay fällt mir eigentlich nichts ein, was ich woanders ordern würde. Ein Wunder eigentlich, dass es das Verb in "ich hab mir dieses Teil geamazont" noch nicht gibt. Diese Warenflut führt allerdings dazu, dass es bei mehreren Dutzend Bestellungen jeden Monat immer aufwändiger wird, die Buchungen zu kontrollieren. Denn aus Datenschutzgründen oder konkurrenzschwächendem Geschäftsgebaren zeigt Amazon sich zugeknöpft bei verschickten Informationen über die bestellten Waren und deren Kosten. Email-Bestätigungen in Gmail geben zum Beispiel nur Nummern einer Order und keine nähere Beschreibung preis, damit Google nichts sammeln kann.
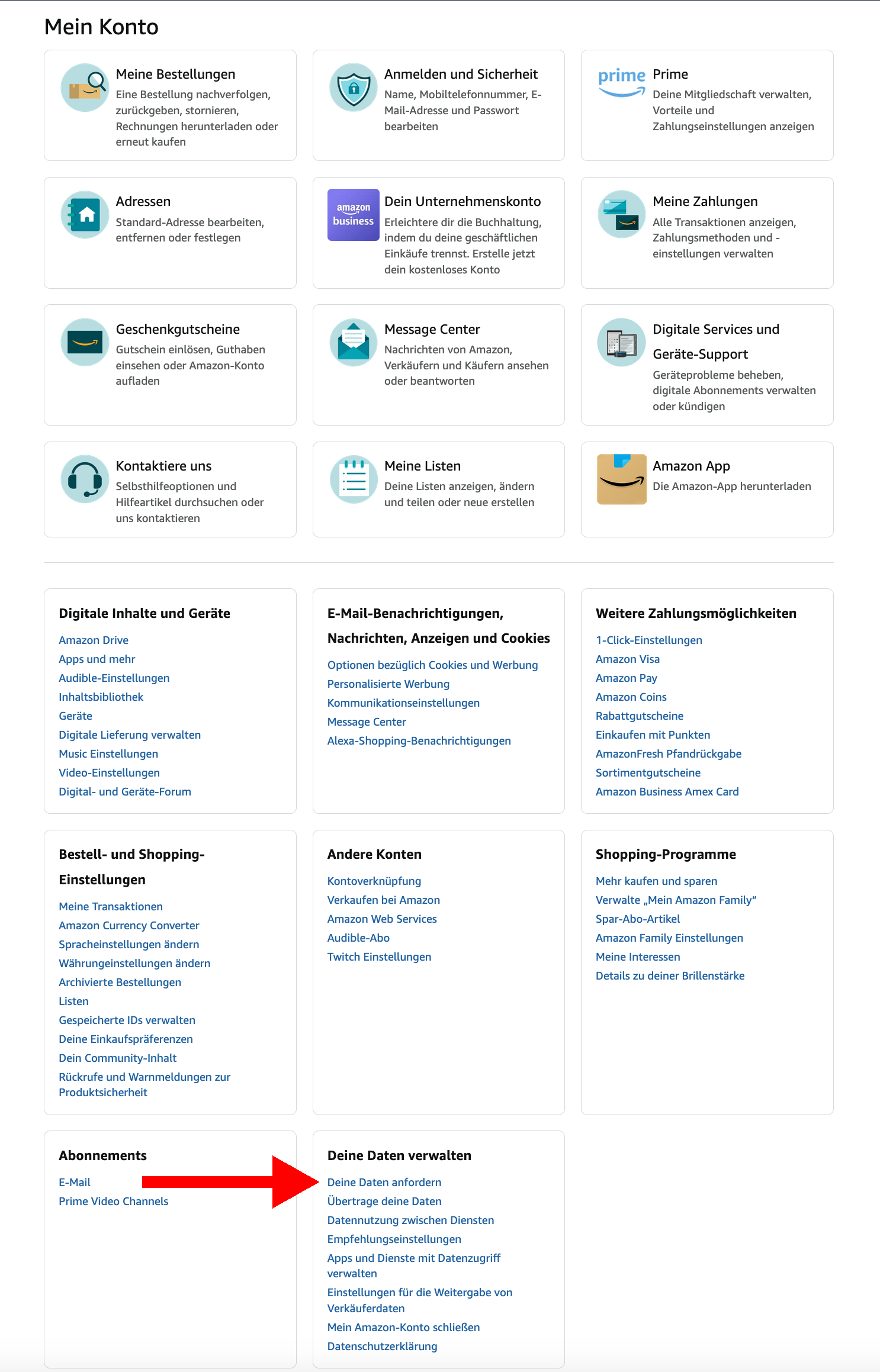
Was wir also brauchen, ist eine Liste bestellter Waren des vergangenen Monats in maschinenlesbarem CSV-Format. Das ging früher über die Webseite, wurde aber von Amazon gemeinerweise umgestellt und man muss nun auf der Seite "Mein Konto" fast ganz am unteren Ende den Link "Deine Daten anfordern" (Abbildung 1) klicken.
| |
| Abbildung 1: Amazon-Bestelldaten in maschinenlesbarem Format anfordern. |
Damit noch nicht genug der Schikane, denn bestätigt der User auf der Folgeseite die Anfrage nach einer Maschinenlesbaren CSV-Datei, antwortet Amazon, nachdem die Anfrage "aus Sicherheitsgründen" auch noch per Email bestätigt wurde, mit dem lapidaren Satz, dass Jeff Bezos Megamarkt die Anfrage zwar erhalten habe, aber die Antwort bis zu einem Monat dauern könne (Abbildung 3). Unglaublich, was der Bestellriese sich hier herausnimmt! Es dauert allerdings selten mehr als 20 Minuten, bis wiederum per Email eine Nachricht vorliegt, die den Link zum Download freigibt.
 |
| Abbildung 2: Endlich liegen die Daten vor. |
Wie Abbildung 2 zeigt, kommt die Datensammlung als ein Dateienduo daher, einmal ein gezip-tes Order-Archiv, und zweitens eine CSV-Datei, die die Einzelverzeichnisse im Archiv wortreich beschreibt. Nutzlos. Im Zip-Archiv aber findet sich ein Sammelsurium verschiedener Unterverzeichnisse, in denen sich endlich das gewünschte CSV-Futter findet (Abbildung 4).
 |
| Abbildung 3: Amazon lässt sich mit der Herausgabe der Daten viel Zeit. |
Digitale Bestellungen (zum Beispiel Kindle-Bücher) liegen nun in Digital-Ordering.1, retournierte Bestellungen normaler Waren in Retail.Customer.Returns.1, und sogar was gerade im Einkaufswagen liegt lässt sich mit CartItems.1+2 in Erfahrung bringen. In den Ordnern Retail.OrderHistory.1.csv und ...2.csv finden sich endlich die gesuchten .csv-Dateien mit den Bestellungen (Abbildung 5). Die Unterteilung in diese zwei Dateien scheint der Aufteilung in verschiedene Amazon-Niederlassungen geschuldet, etwa wenn man wie ich sowohl bei Amazon.com als auch Amazon.de bestellt. Mit der Masse an Bestelldaten, die bei meinem Early-Adopter-Account bis ins Jahr 1997 zurückreichen, lassen sich nun allerhand statistische Auswertungen anstellen. Packen wir's an!
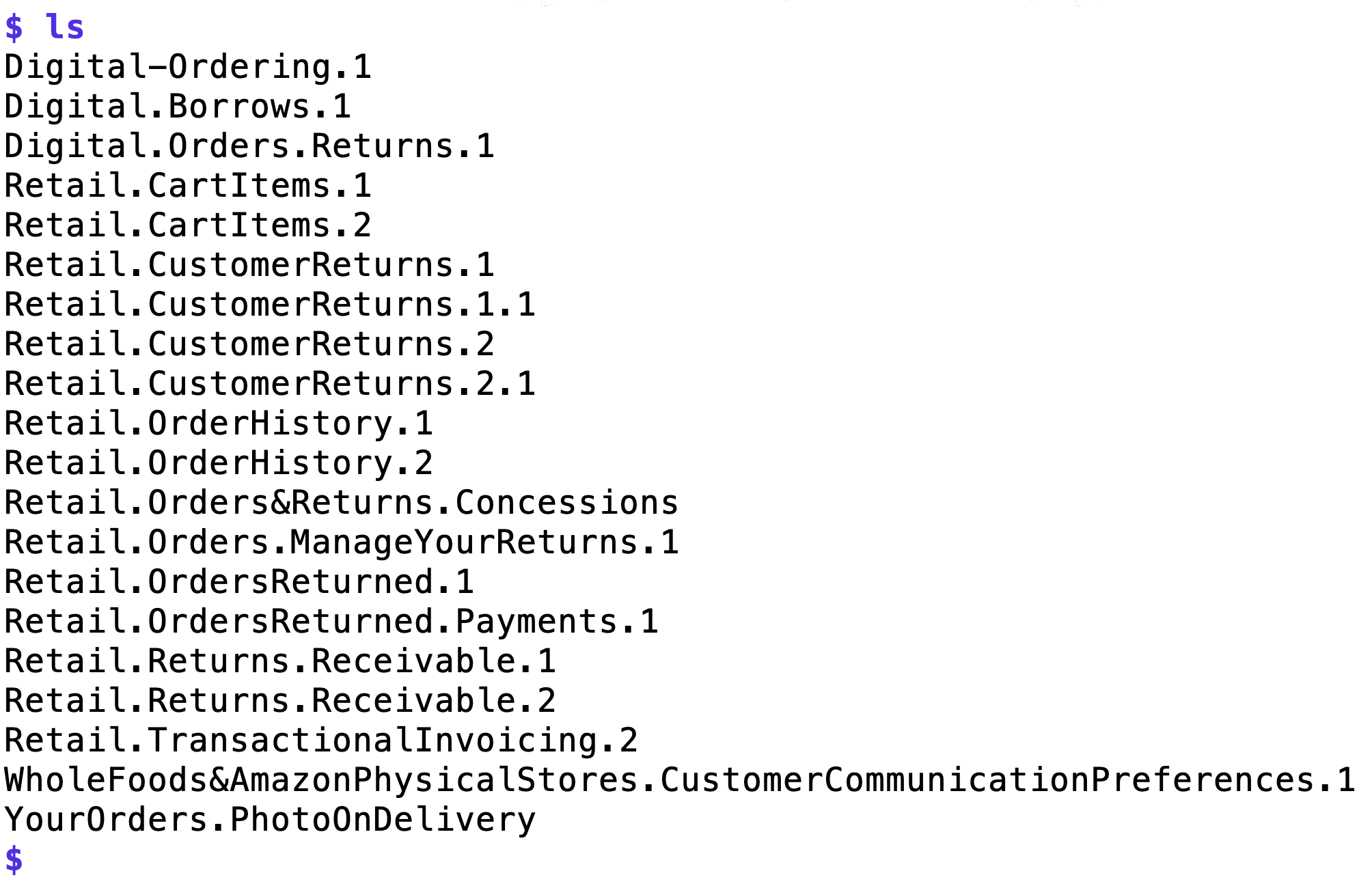 |
| Abbildung 4: Die gesammelten Daten liegen in separaten Bereichen. |
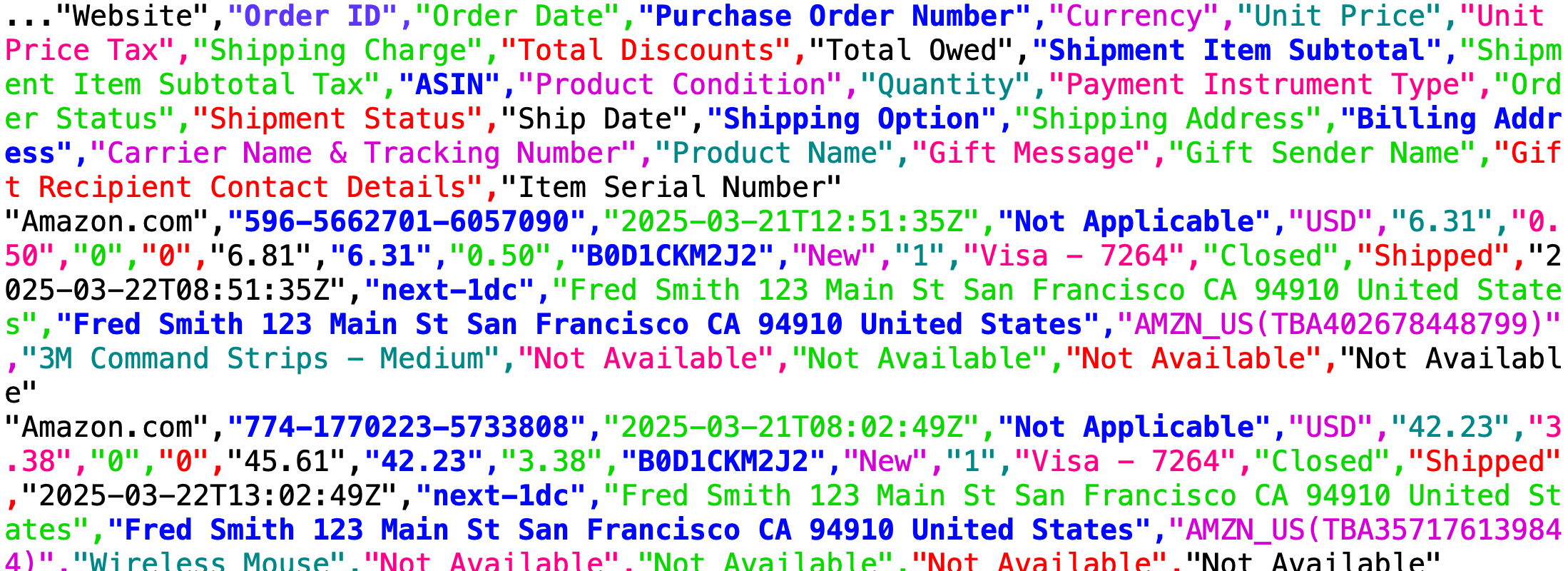 |
| Abbildung 5: Amazon-Bestellungen als .csv |
Zum Einlesen der Daten schnappt sich ParseHistoryFile() ab Zeile 30 in Listing 1 als erstes den Namen der History-Datei und öffnet sie in Zeile 31. Was nun das .csv-Format anbelangt, scheint man bei Amazon in einer Blase zu leben, denn die Datei startet mit drei binären Zeichen, die normale .csv-Parser aus der Bahn werfen (Abbildung 6). Listing 1 springt aus diesem Grund mit Seek() drei Zeichen nach vorne, bevor es die Daten dem Paket encoding/csv überreicht.
 |
| Abbildung 6: Am Anfang der .csv-Datei stehen ungültige Zeichen |
Gos CSV-Parser kennt keine Gnade und da sich in Amazons CSV-Salat auch öfter mal Fehler finden, wie zum Beispiel Felder, die von einer auf die nächste Zeile einfach durch Abwesenheit glänzen, oder Kommentarfelder, die sich über mehrere Zeilen erstrecken, liest Listing 1 die Daten nicht mit wie sonst üblich mit ReadAll() ein, sondern zeilenweise. So kann es Fehler melden, falls mal eine Zeile nicht passt, aber dann mit der nächsten, meist richtig formatierten, fortfahren.
01 package main
02 import (
03 "encoding/csv"
04 "fmt"
05 "io"
06 "os"
07 "time"
08 "go.uber.org/zap"
09 )
10 type Order struct {
11 Total int64
12 Item string
13 Id string
14 At time.Time
15 Shipped time.Time
16 }
17 type Orders struct {
18 Orders []Order
19 Log *zap.Logger
20 }
21 func NewOrders() *Orders {
22 s := Orders{
23 Log: zap.NewNop(),
24 }
25 return &s
26 }
27 func (s *Orders) AddOrder(o Order) {
28 s.Orders = append(s.Orders, o)
29 }
30 func (s *Orders) ParseHistoryFile(filename string) error {
31 file, err := os.Open(filename)
32 if err != nil {
33 return err
34 }
35 defer file.Close()
36 _, err = file.Seek(3, os.SEEK_CUR)
37 if err != nil {
38 return err
39 }
40 reader := csv.NewReader(file)
41 line := 0
42 for {
43 record, err := reader.Read()
44 if err != nil {
45 if err == io.EOF {
46 break
47 }
48 return err
49 }
50 line += 1
51 if line == 1 {
52 continue
53 }
54 if len(record) > 23 {
55 at, err := timeParse(record[2])
56 if err != nil {
57 s.Log.Error("Can't parse",
58 zap.String("order time", record[2]))
59 }
60 shipped, err := timeParse(record[18])
61 if err != nil {
62 s.Log.Error("Can't parse",
63 zap.String("ship time", record[18]))
64 }
65 amt, err := intFromAmount(record[9])
66 if err != nil {
67 err = fmt.Errorf("Line %d: %s", line, err)
68 return err
69 }
70 entry := Order{
71 Item: record[23],
72 At: at,
73 Shipped: shipped,
74 Id: record[1],
75 Total: amt,
76 }
77 s.AddOrder(entry)
78 } else {
79 return fmt.Errorf("Not enough fields: %v", record)
80 }
81 }
82 return nil
83 }
Die Zeile 50 bis 53 in Listing 1 zeigen übrigens, dass Go keinen Wert auf kompakten Code legt, sondern zu simplen, klaren Kontrollstrukturen anregt. Erst erhöht Zeile 50 die Nummer der gerade beabeiteten CSV-Zeile um 1, worauf Zeile 51 prüft, ob es sich um Zeile Eins, also die zu verwerfende Headerzeile handelt, und die Anweisung continue innerhalb einer if-Bedingung sie in diesem Fall tatsächlich verwirft. Vier Zeilen, für Programmlogik, die sich in C in einer Zeile machen ließe! Zwar erlaubt Go das erhöhen eines Zählers um Eins mit ++, aber line++ gibt keinen Wert zurück, der sich wie in C mit einem cleveren if(++line == 1) continue in eine platzsparende Kontrollstruktur einbauen ließe. Nicht zu reden davon, dass Go keine Kurzform einer einzeiligen if-Bedingung zulässt, die Klammern müssen sein, schließlich soll der Leser des Programmtexts bekannte Muster erkennen und nicht lang darüber nachdenken müssen, was bei einem Code-Snippet eigentlich gemeint ist.
Warum überhaupt die Zeilen mitzählen? Erstens lässt sich so die Header-Zeile mit den Kolumnentiteln ausfiltern wenn der Zähler auf 1 steht. Zweitens ist es unheimlich nervig, eine Fehlermeldung wie "Can't parse amount" zu erhalten, ohne die Zeile in der CSV-Datei, deren Betragsfeld unlesbares Kauderwelsch enthält.
Aus den 28 Feldern jeder CSV-Zeile des Amazon-Formats für die Bestell-Historie sollen für die Statistik nur die Bestellnummer (Feld Nummer 2), das Orderdatum (3), das Versanddatum (19), die Produktbeschreibung, sowie der Gesamtbetrag (10) interessieren. Alle liefert der CSV-Parser als Strings in Go zurück, was etwas Arbeit erfordert, um sie in korrekte Datentypen umzumodeln. Listing 2 definiert hierzu die Hilfsfunktionen timeParse() für die Zeitstempel nach RFC3339 sowie die Beträge, die ein Programm wegen Rechengenauigkeit niemals als Float speichern sollte, sonder die Pfennigbeträge als Integer-Werte. Die Hilfsfunktion intFromAmount() parst hierzu den Betragsstring als Float, multipliziert den Wert mal 100, und gibt das Ergebnis als int64 zurück.
01 package main
02 import (
03 "strconv"
04 "strings"
05 "time"
06 )
07 func intFromAmount(s string) (int64, error) {
08 found := int64(0)
09 s = strings.ReplaceAll(s, "$", "")
10 fl, err := strconv.ParseFloat(strings.ReplaceAll(s, ",", ""), 64)
11 if err != nil {
12 return found, err
13 }
14 return int64(fl * 100), nil
15 }
16 func timeParse(s string) (time.Time, error) {
17 spLoc := strings.LastIndex(s, " ")
18 if spLoc != -1 {
19 s = s[spLoc+1:]
20 }
21 dt, err := time.Parse(time.RFC3339, s)
22 if err != nil {
23 return time.Time{}, err
24 }
25 return dt, nil
26 }
Der Rest des Codes in Listing 1 ist Boilerplate-Objektorientierung in Go. Der Konstruktor NewOrders() ab Zeile 21 gibt einen Pointer auf die Struktur Orders zurück, die einen Array-Slice von Bestellungen in Form von Order-Strukturen enthält. Die Funktion AddOrder() ab Zeile 27 hängt einen frisch geparsten neuen Eintrag ans Ende des Arrays an. Damit sich das OO-Konstrukt wahlweise stumm oder gesprächig geben kann, hängt in der Objektstrukur Orders auch noch ein Zap-Logger. Der gibt später beim Parsen Fehlermeldungen aus, falls mal eine CSV-Zeile einen Fehler enthält. Da der Konstruktor NewOrders() den Logger aber in Zeile 23 als zap.NewNop() initialisiert, geben die Logzeilen zunächst einmal gar nichts aus. Nur wenn das Hauptprogramm die (global zugängliche) Instanzvariable Log des Objekts später auf einen aktiven Zap-Logger setzt, wachen die Log-Schreiber in den Zeilen 57 und 62 auf, und schreiben ihre Fehlermeldungen dorthin, wo der Logger es befiehlt. So kann ein Hauptprogramm den Code einbinden, ohne überhaupt von der Existenz des Loggers zu wissen. Ist es hingegen so schlau, das Log-System auf Debug oder Info einzustellen, erwacht der schlafende Code zum Leben.
Listing 3 nutzt die Funktionen der Orders-Struktur in Listing 1, um alle in der Order-Historie aufgelisteten Waren formatiert auszudrucken. Dazu iteriert es nach dem Einlesen der CSV-Datei mit ParseHistoryFile() in der For-Schleife ab Zeile 12 über alle gelieferten Orderobjekte. Das Bestelldatum in At liegt als Zeitstempel vor und Gos Formatstring "2006-01-02" macht ein kompaktes Datum mit Jahr, Monat und Tag daraus. Aus dem int64-Wert für den Bestellwert formt float64 eine Fließkommazahl und die Teilung durch 100 macht aus den Pfennigbeträgen richtige Währungseinheiten.
01 package main
02 import (
03 "fmt"
04 )
05 func main() {
06 histFile := "Retail.OrderHistory.1.csv"
07 orders := NewOrders()
08 err := orders.ParseHistoryFile(histFile)
09 if err != nil {
10 panic(err)
11 }
12 for _, o := range orders.Orders {
13 fmt.Printf("%s %5.2f %.60s\n",
14 o.At.Format("2006-01-02"),
15 float64(o.Total)/100,
16 o.Item,
17 )
18 }
19 }
Den Aufruf von go build mit den drei Source-Dateien, um daraus ein Binary zu erzeugen, zeigt Abbildung 7. Von der Kommandozeile aus aufgerufen, listet list nun alle 4109 Bestellungen auf, die es in meiner bis 1997 zurückreichenden Order-Historie findet. Damals gab es ja bei Amazon nur Bücher zu kaufen, und die mit tail gefilterte Ausgabe unten zeigt meine damaligen Neigungen: Ratgeber zum Erstellen der amerikanischen Einkommensteuererklärung und Fachbücher über die Regeln in rätselhaften amerikanischen Sportarten wie American Football. Schließlich war ich damals neu im Land! Die mit head gefilterten aktuellsten Bestellungen im März 2025 zeigen nur hingegen Gadgets und elektronischen Bastlerbedarf.
 |
| Abbildung 7: Amazon-Bestellungen des Autors zwischen 1997 und 2025 |
Gefühlsmäßig ist Amazon über die Jahre immer schneller geworden bei der Abwicklung meiner Bestellungen. Aber stimmt das wirklich? In der CSV-Datei stecken die Daten dafür, um dies zu überprüfen, denn dort stehen im dritten Feld das Bestelldatum und im Feld Nummer 19 das Versanddatum. Die Differenz der beiden Zeitstempel ist die Bearbeitungszeit.
Nun könnte man dies ohne weiteres in Go erledigen, allerdings zöge sich der Code etwas in die Länge. Viel eleganter geht das in der Programmiersprache R, die für statistische Auswertungen geradezu geschaffen wurde. Listing 4 zeigt den kompakten Code, der eine PNG-Datei mit dem Graphen nach Abbildung 8 erzeugt.
Die Zeilen einer CSV-Datei auszulesen und bestimmte Felder herauszupicken liegt im Naturel der Sprache R. Zeile 8 zieht dann die beiden Datumswerte voneinander ab. Zeile 9 filtert Bestellungen aus, die erst nach 10 Tagen verschickt wurden, denn die Statistik sollen nur durchschnittliche Bestellungen interessieren. Manche seltene Waren sind eben erst nach einigen Wochen vorrätig.
01 #!/usr/local/bin/Rscript
02 library(ggplot2)
03 library(dplyr)
04 library(lubridate)
05 orders <- read.csv("Retail.OrderHistory.1.csv", stringsAsFactors = FALSE)
06 orders$OrderDate <- ymd_hms(orders[[3]], tz = "UTC")
07 orders$ShipDate <- ymd_hms(orders[[19]], tz = "UTC")
08 orders$ShippingDelay <- as.numeric(difftime(orders$ShipDate, orders$OrderDate, units="days"))
09 orders <- orders %>% filter(ShippingDelay <= 10)
10 orders$Year <- year(orders$OrderDate)
11 avg_delay <- orders %>%
12 group_by(Year) %>%
13 summarise(AverageDelay = mean(ShippingDelay))
14 png("delay.png", width = 800, height = 600)
15 ggplot(avg_delay, aes(x = Year, y = AverageDelay)) +
16 geom_line(color = "blue") +
17 geom_point(color = "red") +
18 labs(title = "Amazon Shipping Delay",
19 x = "Year",
20 y = "Average Shipping Delay (days)") +
21 theme_minimal()
Abbildung 8 zeigt, das in der Amazon-Zentrale irgendwann so um 2006 herum anscheinend ein Schalter umgelegt wurde, der die durchschnittliche Bearbeitungszeit von drei Tagen auf einen Tag reduzierte. Dann schwankte sie über ein Jahrzehnt lang um einen Tag herum, bis 2021 weitere drastische Verbesserungen in der Abwicklung erfolgten, die die Verzögerung weiter halbierten. Heutzutage erfolgt der Versand in den meisten Fällen praktisch sofort.
Manche Bestellungen verschickt Amazon auf getrennten Wegen. In diesen Fällen stehen in der Kolumne "Shipping Date" zwei Zeitstempel, getrennt durch zwei Leerzeichen und dem Wort "AND". R ignoriert derartige Einträge einfach, für die Statistik sollen diese Spezialfälle keine Rolle spielen. Auch eliminiert Zeile 9 in Listing 4 Ausreißer, in dem es Bestellungen, deren Versand mehr als 10 Tage dauerte. Manche Waren, besonders verrückt billige Sonderangebote, haben eben längere Lieferzeiten.
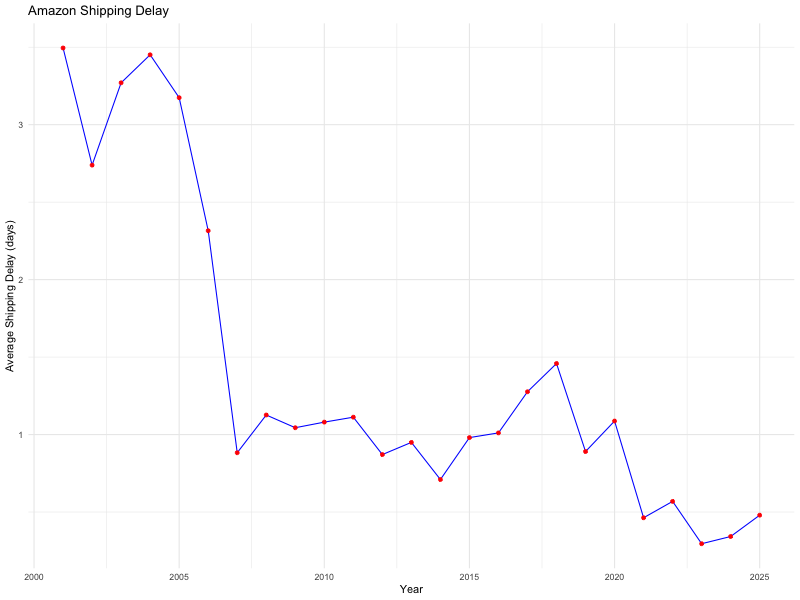 |
| Abbildung 8: Amazons Bearbeitungszeit zum Verschicken von Bestellungen |
Aber mit Orderdaten von mehr als 20 Jahren lassen sich noch weitere Analysen fahren. An welchen Wochentagen klicke ich zum Beispiel am häufigsten auf den Buy-Button?
01 package main
02 import (
03 "time"
04 )
05 func main() {
06 histFile := "Retail.OrderHistory.1.csv"
07 orders := NewOrders()
08 err := orders.ParseHistoryFile(histFile)
09 if err != nil {
10 panic(err)
11 }
12 xVals := make([]string, 7)
13 yVals := make([]float64, 7)
14 for i := 0; i < 7; i++ {
15 xVals[i] = time.Weekday(i).String()
16 }
17 for _, o := range orders.Orders {
18 wdi := int(o.At.Weekday())
19 yVals[wdi]++
20 }
21 barChart("wday.png", "Order Weekdays", xVals, yVals)
22 }
Listing 5 ist wieder eine Go-Applikation und liest mit ParseHistoryFile() aus Listing 1 die CSV-Daten ein. Zur grafischen Darstellung der Wochentage wählt es eine Balkengrafik, die wie in Abbildung 11 gezeigt, die X-Achse mit Wochentagen von Sonntag bis Samstag beschriftet und auf der Y-Achse für jeden Wochentag einen Balken malt, dessen Höhe der Anzahl gezählter Bestellungen an diesem Tag entspricht.
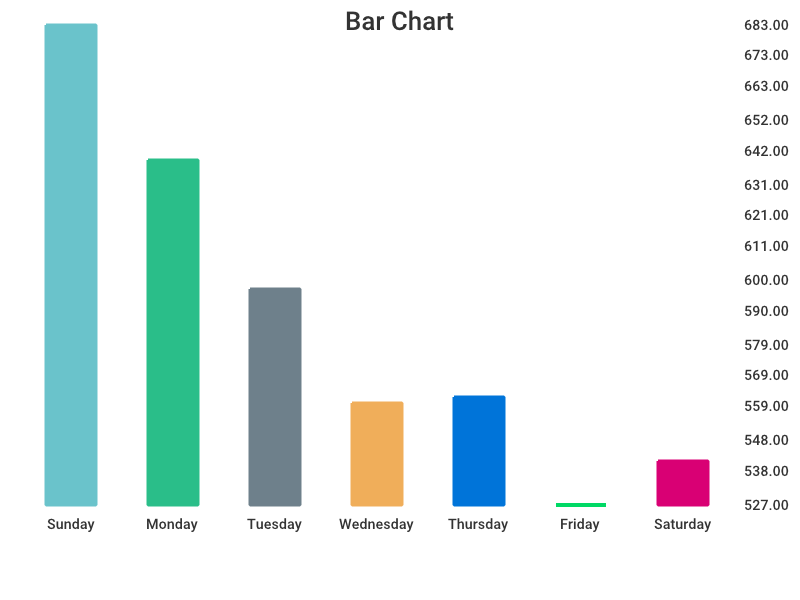 |
| Abbildung 9: An welchen Wochentagen häufen sich Bestellungen? |
Hierzu zählt die For-Schleife ab Zeile 14 in Listing 5 von Null bis Sechs und legt im Array Slice xVals die englischen Strings für die Wochentage ab, indem es die Funktion Weekday() aus Gos time-Paket befragt.
Zur Berechnung der Balkenhöhe iteriert die For-Schleife ab Zeile 17 durch alle Bestellungen, bestimmt mit Weekday() den Wochentags-Index des Bestelldatums o.At und zählt in Zeile 19 das entsprechende Array-Element um Eins hoch.
Eine gute Frage ist übrigens, warum time.Weekday() einmal einen String (z.B. "Monday") zurückgibt und einmal einen Integerwert (z.B. 1). Des Rätsels Lösung ist, dass die Funktion eine Variable from Typ time.Weekday zurückgibt, die als Typ int implementiert ist und mit dem Schlüsselwort iota Werte zwischen 0 und 7 annimmt. Ein int(x) wird also den Integerwert liefern, während "%s" in Printf() den Aufruf der Methode String() des Typs auslöst, die (entsprechend der Lokal-Einstellungen) den Namen des Wochentags als String zurückgibt.
Schöne Balkengrafen zu erstellen ist auch in Go nicht schwer, dank Paketen wie go-chart, das sich von Github hereinziehen lässt. Die Funktion barChart() in Listing 6 nimmt neben dem gewünschten Namen der Ausgabedatei und einem String mit der Kopfzeile des Diagramms zwei Array-Slices entgegen.
01 package main
02 import (
03 "os"
04 "github.com/wcharczuk/go-chart/v2"
05 )
06 func barChart(outFile string, header string, xVals []string, yVals []float64) {
07 bars := []chart.Value{}
08 for i, x := range xVals {
09 bars = append(bars,
10 chart.Value{Label: x, Value: yVals[i]})
11 }
12 barChart := chart.BarChart{
13 Title: header,
14 Height: 600,
15 Width: 800,
16 Bars: bars,
17 }
18 f, err := os.Create(outFile)
19 if err != nil {
20 panic(err)
21 }
22 defer f.Close()
23 barChart.Render(chart.PNG, f)
24 }
In xVals kommt ein Array-Slice von Strings, in yVals eines von Float64-Werten für die Balkenhöhen herein. Zum Erzeugen der Grafik modelt die Funktion die Daten in einen Array von chart.Value-Strukturen um und überreicht sie der chart.BarChart-Struktur ab Zeile 12. Dann muss Zeile 18 nur noch die zu erzeugende PNG-Datei anlegen und Render() in Zeile 23 malt alles, inklusive Balken in zufällig gewählten Farben, Achsen und deren Beschriftung.
Zum Erzeugen des Go-Binaries muss go build alle vier Source-Dateien (wday.go, chart.go, orders.go, utils.go) zusammenbinden, nachdem der Compiler vorher mit go mod init wday und go mod tidy angewiesen wurde, ein Go-Modul zu definieren und dessen Abhängigkeiten von Github einzuholen.
Abbildung 10 zeigt die Häufung von Bestellungen, abhängig vom Monat des Eingangs. Zur Erstellung der Grafik dient das Programm in Listing 7, das statt des Wochentags mit Weekday() den Monat mit Month() extrahiert und aufsummiert. Erwartungsgemäß geht es in der Vorweihnachtszeit heiß her, mit Sonderangeboten ab Black Friday im November, aber auch während des Winterschlussverkaufs ab Januar klicke ich anscheinend zügelloser auf den "Buy"-Button.
 |
| Abbildung 10: Einige Monate sind prädestiniert für Amazon-Bestellungen |
01 package main
02 import (
03 "time"
04 )
05 func main() {
06 histFile := "hist-org.csv"
07 orders := NewOrders()
08 err := orders.ParseHistoryFile(histFile)
09 if err != nil {
10 panic(err)
11 }
12 xVals := make([]string, 12)
13 yVals := make([]float64, 12)
14 for i := 0; i < 12; i++ {
15 xVals[i] = time.Month(i + 1).String()
16 }
17 for _, o := range orders.Orders {
18 mi := int(o.At.Month()) - 1
19 yVals[mi]++
20 }
21 barChart("month.png", "Order Months", xVals, yVals)
22 }
 |
| Abbildung 11: Auch alle Zustellfotos sammelt Amazon |
Der amerikanische Amazon packt der Sammlung noch ein Schmankerl bei: Wenn der Paketbote die Order an der Haustür abliefert, schießt er ein Foto zum Beweis dafür, dass die Bestellung zugestellt wurde. Das Foto zeigt dann die Haustür oder den Eingangsbereich eines Mietshauses mitsamt dem dort drapierten Amazon-Umschlag oder -Paket. Das Verfahren hilft auch dabei, die von schusseligen Zustellern am falschen Ort abgelieferten Pakete aufzustöbern. Einmal gelang es mir so, ein verlorengeganges Paket in der Küche eines nahegelegenen Restaurants aufzuspüren ([2]).
Amazon-Zusteller in Deutschland machen (wahrscheinlich aus Datenschutzgründen) keine Zustellfotos, aber beim amerikanischen Original liegen diese Kunstwerke den heruntergeladenen Daten im Ordner YourOrders.PhotoOnDelivery als JPG-Bilder bei. Wer Spaß daran hat, kann daraus eine künstlerisch hochwertige Collage fertigen (Abbildung 11).
Soweit einige praktische Beispiele zur Illustration des Kaufverhaltens auf Amazon, aber das war erst der Anfang. Wie wäre es mit einer Grafik, die die monatlichen Ausgaben illustriert? Oder eine Applikation, die die Bestelldaten mit einem Kontoauszug oder der Kreditkartenabrechnung abgleicht? Oder einer Budget-Software wie Ynab beibringt, Kontoabbuchungen mit detaillierten Bestelldaten zu versehen? Der Kreativität sind mal wieder keine Grenzen gesetzt.
Listings zu diesem Artikel: http://www.linux-magazin.de/static/listings/magazin/2025/06/snapshot/
"Amzon-Zusteller auf Abwegen", https://usarundbrief.com/156/p3.html
 |
Michael Schilliarbeitet als Software-Engineer in der San Francisco Bay Area in Kalifornien. In seiner seit 1997 laufenden Kolumne forscht er jeden Monat nach praktischen Anwendungen verschiedener Programmiersprachen. Unter mschilli@perlmeister.com beantwortet er gerne Ihre Fragen. |
Hey! The above document had some coding errors, which are explained below:
Unknown directive: =desc