
Der Monitor Nagios ist nicht nur für Großinstallationen mit hunderten von Systemen unverzichtbar, sondern eignet sich auch für den Hausgebrauch.
Was tun, wenn der technisch eher desinteressierte Lebenspartner aus dem anderen Zimmer ``Mein Internet geht nicht!'' ruft? Man könnte mühsam nachforschen, ob der Router ordnungsgemäß mit dem Service-Provider kommuniziert, der DNS-Server erreichbar ist und die eigene Website zuverlässig vor sich hinschnurrt. Viel einfacher wäre es allerdings, einen Blick auf die Nagios-Seite in Abbildung 1 zu werfen, um anhand der grünen und roten Felder festzustellen, wo der Fehler steckt.
Nagios ist ein Überwachungsprogramm, das laufend Tests ausführt, die Ergebnisse speichert, graphisch ansprechend auf einer Webseite aufbereitet, Alarme auslöst und Aktionen einleitet. Die Tests werden von externen Plugins ausgeführt. Auf www.nagios.org steht eine reiche Auswahl von Standardplugins zur Überwachung von Websites, Datenbanken, Netzwerken und vielem mehr zur Verfüung. Für spezielle Bedürfnisse lassen sich einfach eigene Plugins als Skripts oder Binaries schneidern.
| |
| Abbildung 1: Die Nagios-Übersichtsseite zeigt an, dass lokale Tests fehlerlos durchlaufen, aber der Router und alle hinter ihm liegenden Systeme nicht ansprechbar sind. |
 |
| Abbildung 2: Nagios produziert einen Graph, der anzeigt, wie oft ein System nicht ansprechbar war. |
Nagios kann zum Beispiel laufend zu prüfen, ob ein Hostingprovider dem Kunden vernünftige Performance mit genügend Spielraum zur Verfügung stellt und nicht einen ``shared'' Server mit zuvielen Websites überheizt. Hat die Nagios-Installation auf dem lokalen Rechner aus Sicherheitsgründen keinen direkten Zugang zum Host des Hostingproviders, installiert man dort einfach einen Agenten.
Das Skript iostat.cgi im CGI-Verzeichnis des Webservers lässt auf
einen HTTP-Request hin auf dem Server das Linux-Kommando iostat ablaufen
und sendet die Ergebnisse als Text über den Webserver zurück an den
anfordernden Nagios-Plugin. Dieser interpretiert das Ergebnis und teilt dann
Nagios über den Exit-Code mit, ob alles im grünen Bereich ist oder
ein Problem aufgetreten ist (Kasten 1).
Kasten 1: Exitwerte eines Nagios-Plugins
Exit-Wert Text Bedeutung
0 OK Alles im grünen Bereich
1 WARNING Service-Problem
2 CRITICAL Kritisches Service-Problem
3 UNKNOWN Problem mit dem Plugin
01 #!/usr/bin/perl -w
02 use strict;
03 use Sysadm::Install qw(:all);
04
05 use CGI qw(:all);
06 use Regexp::Common;
07 use Sysadm::Install qw(:all);
08
09 my($stdout, $stderr, $rc) =
10 tap "iostat", 1, 2;
11
12 $stdout =~ /avg-cpu.*?avg-cpu/gs;
13
14 print header();
15
16 for my $key (qw(user nice sys
17 iowait idle)) {
18 if($stdout =~
19 /\G.*?($RE{num}{real})/gs) {
20 printf "%s %s ", $key, $1;
21 }
22 }
Das CGI-Skript iostat.cgi ruft über die Funktion tap des
Moduls Sysadm::Installs vom CPAN das Linux-Kommando
iostat mit den Parametern 1 2 auf.
Wegen des interval-Wertes von 1 und
des count-Wertes von 2 führt es zwei Messungen von CPU-Performance und
Festplatten-I/O durch und erzeugt eine Ausgabe
gemäß Abbildung 3. Die erste Messung gibt Mittelwerte seit dem
letzten Reboot zurück, während die zweite die für Nagios interessanteren
aktuellen Werte zeigt, die über eine Sekunde gemittelt wurden.
Der Wert in der Spalte %idle gibt an, wie lange die CPU frei zur Verfügung
stand und %iowait misst, wie lange die CPU auf die Festplatte warten
musste. Aus der Sicht des Kunden ist also ein hoher Wert für %idle
günstig (geringe CPU-Auslastung) und ein möglichst geringer Wert für
%iowait (niemand rödelt exzessiv auf der Platte herum).
 |
|
Abbildung 3: Das Kommando C |
Das CGI-Skript iostat.cgi liest die Ausgabe von iostat,
wirft die erste Messung weg, parst mit dem regulären Ausdruck
$RE{num}{real} aus dem Regexp::Common-Fundus die Zahlenwerte
und gibt (nach dem obligatorischen HTTP-Header) den Text
user 2.99 nice 0.00 sys 0.00 iowait 0.00 idle 96.52
zurück. Die sogenannte zero-width assertion \G sorgt dafür, dass der
Regex-Engine nicht jedesmal zum Textanfang zurückspringt, sondern den
Suchvorgang direkt hinter dem letzten Treffer fortsetzt. Auf der Nagios-
Seite ruft der Plugin in Listing
check_iostat mit LWP::Simple das gerade
vorgestellte CGI-Skript auf dem Server auf, schnappt sich die Ausgabezeile
und zerlegt sie mit split in Einzelfelder, die er im Hash %values
ablegt. Ist die CPU zu weniger als 50% verfügbar, meldet der Plugin den
Zustand ``critical'', sind es weniger als 70%, wird mit ``warning'' nur eine
Verwarnung ausgesprochen. Analoges gilt für die gemessenen iowait-Werte,
bei denen die Grenzwerte bei 10% und 20% liegen.
Das Modul Nagios::Clientstatus vom CPAN erleichtert die Arbeit
am Plugin etwas,
da es prüft, ob alle erforderlichen Parameter an das Plugin-Skript
hereingereicht wurden. Ausserdem kann man der Methode exitvalue()
Strings wie ``warning'' mitgeben und muss sich nicht merken, dass dies in der
Nagios-Welt der Wert ``1'' ist. Von der Kommandozeile aus aufgerufen
zeigt der Plugin nun folgende Ausgabe:
$ check_iostat -url=http://perlmeister.com/cgi/iostat.cgi
IOSTAT OK - user 2.99 nice 0.00 sys 0.00 iowait 0.00 idle 96.52
Nagios wird später den Plugin genau so aufrufen und sowohl den Exit-Wert interpretieren als auch den auf STDOUT angegebenen Text anzeigen. Zu beachten ist, dass Nagios::Clientstatus mindestens Version 2.35 von Getopt::Long benötigt.
01 #!/usr/local/bin/perl
02 use strict;
03 use LWP::Simple;
04 use Log::Log4perl qw(:easy);
05 use Nagios::Clientstatus;
06
07 my $version = "0.01";
08 my $ncli = Nagios::Clientstatus->new(
09 help_subref =>
10 sub { print "usage: $0 url\n" },
11 version => $version,
12 mandatory_args => [ "url" ],
13 );
14
15 my $url = $ncli->get_given_arg("url");
16
17 my $data = get $url;
18
19 unless($data) {
20 print "Failed to get $url\n";
21 exit $ncli->exitvalue("unknown");
22 }
23
24 my %values = split ' ', $data;
25
26 my $status =
27 $values{idle} < 5 ? "critical" :
28 $values{idle} < 10 ? "warning" :
29 $values{iowait} > 20 ? "critical" :
30 $values{iowait} > 10 ? "warning" :
31 "ok";
32
33 print "IOSTAT ", uc($status), " - $data\n";
34
35 exit $ncli->exitvalue($status);
Um den neuen Plugin in eine existierende Nagios-Installation
einzuhängen, muss das Skript check_iostat
ausführbar ins Verzeichnis /usr/local/nagios/libexec kopiert werden.
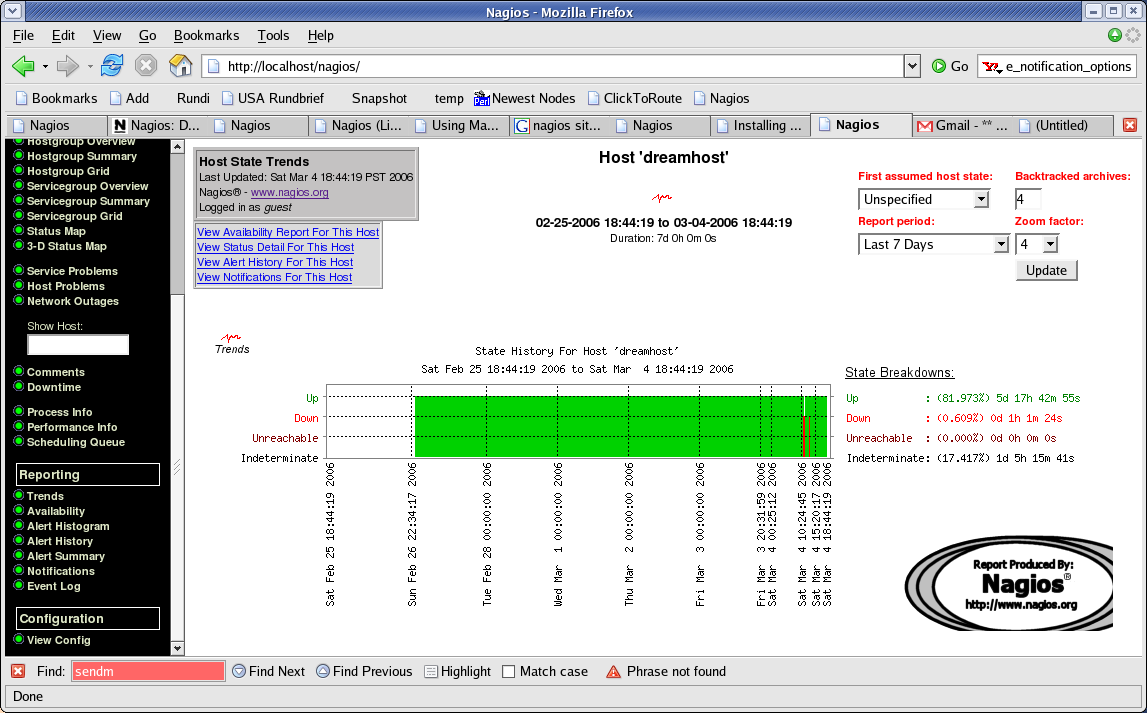
Die Nagios-Konfiguration wird gemäß Abbildung 4 um ein Template namens
ez-service erweitert, das später auch die Definition weiterer Plugins
vereinfachen wird. Es ist gängige Praxis in Nagios-Konfigurationen, dass
man Service- (und auch andere) Templates definiert, die am
Eintrag register 0 erkennbar sind und von tatsächlichen
Service-Definitionen später um spezielle Einträge erweitert werden.
Mit define service wird unten in Abbildung 4 der neue
iostat-``Service'' definiert. Er bindet
das vorher definierte Template mit use ez-service ein und übernimmt so
zahlreiche Parameter für Testabläufe, Email-Benachrichtigungen und vieles
mehr. notification_interval 0 verhindert zum Beispiel, dass für ein
Problem mehrere Emails geschickt werden. normal_check_interval ist
die Zeitabstand zwischen ausgeführten Service-Tests in Minuten.
max_check_attempts bestimmt,
nach wie vielen fehlgeschlagenen Tests Nagios endlich eine
Benachrichtigung schickt. Die service_notification_options legen fest,
bei welchen Zustandsänderungen Emails verschickt werden:
w=warning, u=unknown, c=critical, r=recovery. Ähnliches gilt für
host_notification_options: u=unknown, d=down, r=recovery.
Ist der Nagios-Server wegen eines Netzwerkproblems selbst
von der Umwelt abgeschnitten, kommt natürlich auch keine Warnungsemail
übers Internet an. In diesem Fall erreicht den erleichterten Admin
dann zumindest die RECOVERY-Email, wenn das Problem behoben ist.
Ein weiteres Feature sind
Event-Handler, die Aktionen definieren, die Nagios ausführt, wenn es ein
Problem feststellt. So lassen sich Probleme wie ein heruntergefallener
Webserver manchmal selbstständig lösen, bevor ein Admin alarmiert wird
und von Hand einschreiten muss.
Ein Service ist in Nagios immer einem Host zugeordnet, den das System
getrennt auf Verfügbarkeit testet. Dessen Definition verlangt weitere
Einträge in der Konfigurationsdatei. Der Eintrag host_name
dreamhost gibt an, dass in der Konfiguration ein ebensolcher Host
konfiguriert wurde. Der Parameter check_command der Service-Definition
spezifiziert den Aufruf des neuen Plugins check_iostat. Dieser wird jedoch
nicht direkt aus der Service-Definition heraus aufgerufen, sondern über ein
weiter oben mit define command konfiguriertes Kommando. Dort wird
die tatsächlich ausgeführte Kommandozeile festgelegt. Der Platzhalter
$ARG1$ wird dort durch den tatsächlich übergebenen URL ersetzt, den
check_command in der Service-Definition dem iostat-Kommando durch ein
Ausrufezeichen getrennt übergab.
Auch die Angabe 24x7 für die Parameter check_period und
notification_period erfordern weitere Einträge, die die
Email des Admins und seine Verfügbarkeit definierten.
Unter [1] ist deswegen
die Beispieldatei eznagios.cfg erhältlich, die man mit
cfg_file=/usr/local/nagios/etc/eznagios.cfg
in die zentrale Konfigurationsdatei nagios.cfg einbinden kann und
damit alle heute besprochenen Einstellungen parat hat. Außerdem definiert
sie gemäß Abbildung 1 weitere Nagios-Tests, die anzeigen,
wie voll verschiedene Festplattenpartitionen sind
oder ob der Router oder der DNS-Server
des Service-Providers noch richtig ticken.
 |
| Abbildung 4: Die Nagios-Konfiguration für den neuen iostat-Plugin |
Ein weiteres Beispiel eines selbstgebauten Nagios-Plugins zeigt
check_temperature. Das Skript kontaktiert die Round-Robin-Datenbank
des in [3] vorgestellten Temperaturfühlers und schlägt Alarm, falls
die Außen- oder Innentemperatur sich außerhalb festgelegter Grenzen
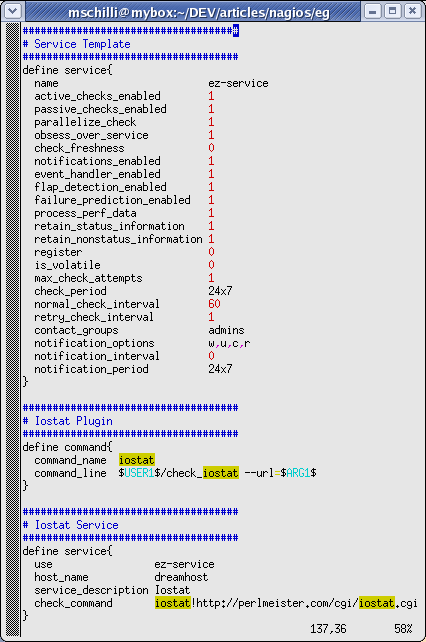
bewegen. Typisch für Nagios-Plugins akzeptiert es Kommandozeilenparameter
für die Grenzwerte, so dass ein Aufruf von
check_temperature -warn=30 -crit=35 -dsname=Inside
auf WARNING schaltet, falls die Innentemperatur über 30 Grad Celsius steigt und CRITICAL ausgelöst wird, falls 35 Grad überschritten werden. Abbildung 5 zeigt die unterschiedlichen Exit-Werte und Ausgaben des Plugins für unterschiedliche Parameter.
Analog zum vorher vorgestellten iostat-Plugin übergibt folgende Service-Konfiguraion dem Skript die Parameter:
check_command check_temperature!25!30!Inside
Der entsprechende Eintrag für das den command-Eintrag sieht so aus:
define command {
command_name check_temperature
command_line $USER1$/check_temperature -warn=$ARG1$ -crit=$ARG2$ -dsname=$ARG3$
}
Die bunte Tabelle in Abbildung 1 zeigt im Mittelteil, dass beide Temperaturtests sich mit 18.8 (innen) und 15.9 (außen) Grad Celsius im grünen Bereich bewegen. Die Wohnung brennt also nicht.
01 #!/usr/bin/perl -w
02 use strict;
03 use RRDTool::OO;
04 use Getopt::Std;
05 use Pod::Usage;
06 use Nagios::Clientstatus;
07
08 my $N = "TEMPERATURE";
09
10 my $nc = Nagios::Clientstatus->new(
11 help_subref => sub { pod2usage() },
12 mandatory_args => [qw(
13 crit warn dsname
14 )],
15 );
16
17 my $rrd = RRDTool::OO->new(
18 file => "/tmp/temperature.rrd" );
19
20 my $dsnames = $rrd->meta_data("dsnames");
21
22 $rrd->fetch_start(
23 start => time() - 6*60,
24 end => time()
25 );
26
27 my $temp;
28
29 if(my($time, @values) =
30 $rrd->fetch_next()) {
31 print localtime $time, ": @values\n";
32 for(my $i=0; $i<@$dsnames; $i++) {
33 if($dsnames->[$i] eq
34 $nc->get_given_arg("dsname")) {
35 $temp = $values[$i];
36 last;
37 }
38 }
39 }
40
41 my $status = "ok";
42
43 if(! defined $temp) {
44 $status = "unknown";
45 }
46 elsif($temp >=
47 $nc->get_given_arg("crit")) {
48 $status = "critical";
49 }
50 elsif($temp >=
51 $nc->get_given_arg("warn")) {
52 $status = "warning";
53 }
54
55 printf "$N %s - %s: %s\n",
56 uc($status),
57 $nc->get_given_arg("dsname"),
58 defined $temp ?
59 sprintf("%.1f", $temp) :
60 "NODATA";
61
62 exit $nc->exitvalue($status);
 |
| Abbildung 5: Ausgaben und Exit-Werte des Temperaturplugins auf unterschiedliche Kommandozeilenparameter |
Die Nagios-2.0-Distribution ist auf www.nagios.com als Tarball verfügbar. Nach dem Auspacken installieren folgende Schritte einen Nagios-Server:
# nagios user/group
$ adduser nagios
$ cd nagios-2.0
$ ./configure
$ make all
# binaries/CGI/HTML
$ make install
# /etc/rc.d/init.d
$ make install-init
# Beispiel-Konfiguration
$ make install-config
Ein gesonderter Tarball [2] enthält die Standard-Plugins für Nagios-2.0,
die in das Verzeichnis /usr/local/nagios/libexec entpackt werden.
Die größte Hürde bei Nagios ist die Konfiguration. Nach der
Installation müssen nicht weniger als sechs (!) verschiedene
Konfigurationsdateien erstellt werden. Zum Glück liegen der
Distribution Beispieldateien bei, die es nur an die örtlichen
Verhältnisse anzupassen gilt. Hierzu benennt man einfach die
im Verzeichnis /usr/local/nagios/etc liegenden Dateien mit
der Endung *.cfg-sample in *.cfg-Dateien um.
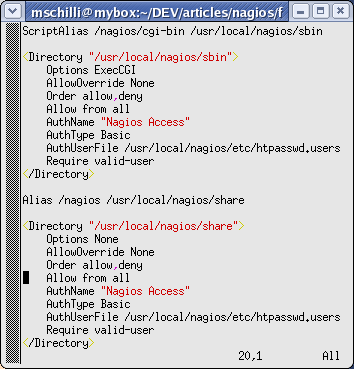 |
| Abbildung 6: Einstellungen in der Webserverkonfiguration für Nagios |
Eine wichtige Rolle spielt die Sicherheit, denn eine Nagios-Installation sollte auf keinen Fall frei zugänglich im Internet stehen. Der Nagios-Webserver wird mit den Einstellungen in Abbildung 6 hergerichtet. Nach einem Start des Nagios-Dämons mit
# /etc/rc.d/init.d/nagios restart
und einem HUP-Signal an den Webserver
sind dann unter http://localhost/nagios die gemessenen Daten und eine
Reihe von Berichtsformaten (Abbildung 2) für per Basic Auth
authentifizierte Benutzer zugänglich. Ist die Nagios-Seite hinter einer
Firewall und nur von vertrauenswürdigen Personen aufrufbar, kann sich diesen
Heckmeck sparen und die Zeilen mit Require valid-user auskommentieren. In
der Nagios-Konfigurationsdatei cgi.cfg sorgen in diesem Fall die Einträge
# cgi.cfg:
default_user_name=guest
authorized_for_system_information=nagiosadmin,guest
authorized_for_configuration_information=nagiosadmin,guest
authorized_for_all_services=nagiosadmin,guest
authorized_for_all_hosts=nagiosadmin,guest
authorized_for_all_service_commands=nagiosadmin,guest
authorized_for_all_host_commands=nagiosadmin,guest
dafür, dass der unauthentifizierte ``Gast'' Zugang zu allen Daten und Service-Kommandos hat. Einen solchen Server aufs Internet zu stellen wäre extrem gefährlich, doch hinter der eigenen Firewall ist's ganz praktisch. Nach allen Änderungen in Konfigurationsdateien sollte man mit
$ cd /usr/local/nagios
$ bin/nagios -v etc/nagios.cfg
zunächst prüfen, ob Fehler in der Konfiguration vorliegen bevor der Dämon neu gestartet wird. Eine gut durchdachte Überwachungsstrategie, die mit Nagios zuverlässig ausgeführt wird, lässt den Admin ruhig schlafen -- es sei denn, ein Alarm geht los. Doch ein Weckruf von Nagios an den Pager ist dem Telefonanruf eines verärgerten Benutzers allemal vorzuziehen.
[Bitte Listing eznagios.cfg Online bereitstellen]
=include eg/eznagios.cfg listing
 |
Michael Schilliarbeitet als Software-Engineer bei Yahoo! in Sunnyvale, Kalifornien. Er hat "Goto Perl 5" (deutsch) und "Perl Power" (englisch) für Addison-Wesley geschrieben und ist unter mschilli@perlmeister.com zu erreichen. Seine Homepage: http://perlmeister.com. |