
Beim Einbau einer neuen Festplatte wähnen sich User im siebten Himmel und es scheint schier unmöglich, diese jemals vollzuschreiben. Angesichts gigantischer Kapazitäten wird allerdings jeder früher oder später zum prassenden Lüderjahn, die Platte füllt sich, und es gilt, Platz zu schaffen, um den Weiterbetrieb zu gewährleisten. Meist liegt es an längst nicht mehr genutzten Riesendateien, die untätig in längst vergessenen Verzeichnissen herumlungern. Den besten "Bang for the Buck" bringt oft die simple Strategie, die größten Verschwender aufzustöbern und die zugehörigen Dateileichen zu löschen.
| |
| Abbildung 1: UI mit speicherintensiven Git-Verzeichnissen |
 |
| Abbildung 2: Aufgefächerte Verzeichnisse zeigen die dicksten Brummer |
Das Go-Programm dieser Ausgabe hilft bei diesem Hausputz, indem es, ausgehend von einem Root-Verzeichnis, die speicherintensivsten Pfade samt dem in ihnen jeweils verbratenen Plattenplatz in Bytes angibt. Wie in Abbildung 1 zu sehen, schaltet das mit dem zu analysierenden Root-Verzeichnis aufgerufene Go-Binary das Terminal in den Grafikmodus und stellt die Speicherpfade als interaktiven Baum dar, dessen grüne Elemente sich per Tastendruck oder Mausklick weiter auffächern lassen, um festzustellen in welchen Unterverzeichnissen die dicksten Brummer liegen (Abbildung 2).
Im vorliegenden Fall nahm sich das Go-Binary spacetree das git-Verzeichnis unter meinem Home-Directory zur Brust und fand heraus, dass darunter etwa 14 Gigabytes an Daten liegen. Mit den Cursor-Tasten oder den vi-Kommandos "j" und "k" (oder auch per Mausklick) lassen sich die grün unterlegten Verzeichnisse anfahren und mit "Enter" auffächern. In Abbildung 2 stellt sich so heraus, dass zum Beispiel das Verzeichnis articles, in dem die Artikel aus 26 Jahren dieser Kolumne liegen, insgesamt fast vier Gigabytes abruft.
Das meiste, etwa 850MB, liegt im git-internen Verzeichnis .git, und der verschwenderschste Artikel ist der Netzwerkprüfer wifi aus der Augustausgabe, allerdings nur, weil noch das zugehörige Snapshot-Video darin verweilt. Weg damit und schon wieder 850MB gespart! Auch der Artikel zum Fortschrittsbalken vom Dezember 2018 enthält die Dateileiche "foo" und "foo.bak", die weggeputzt gehören.
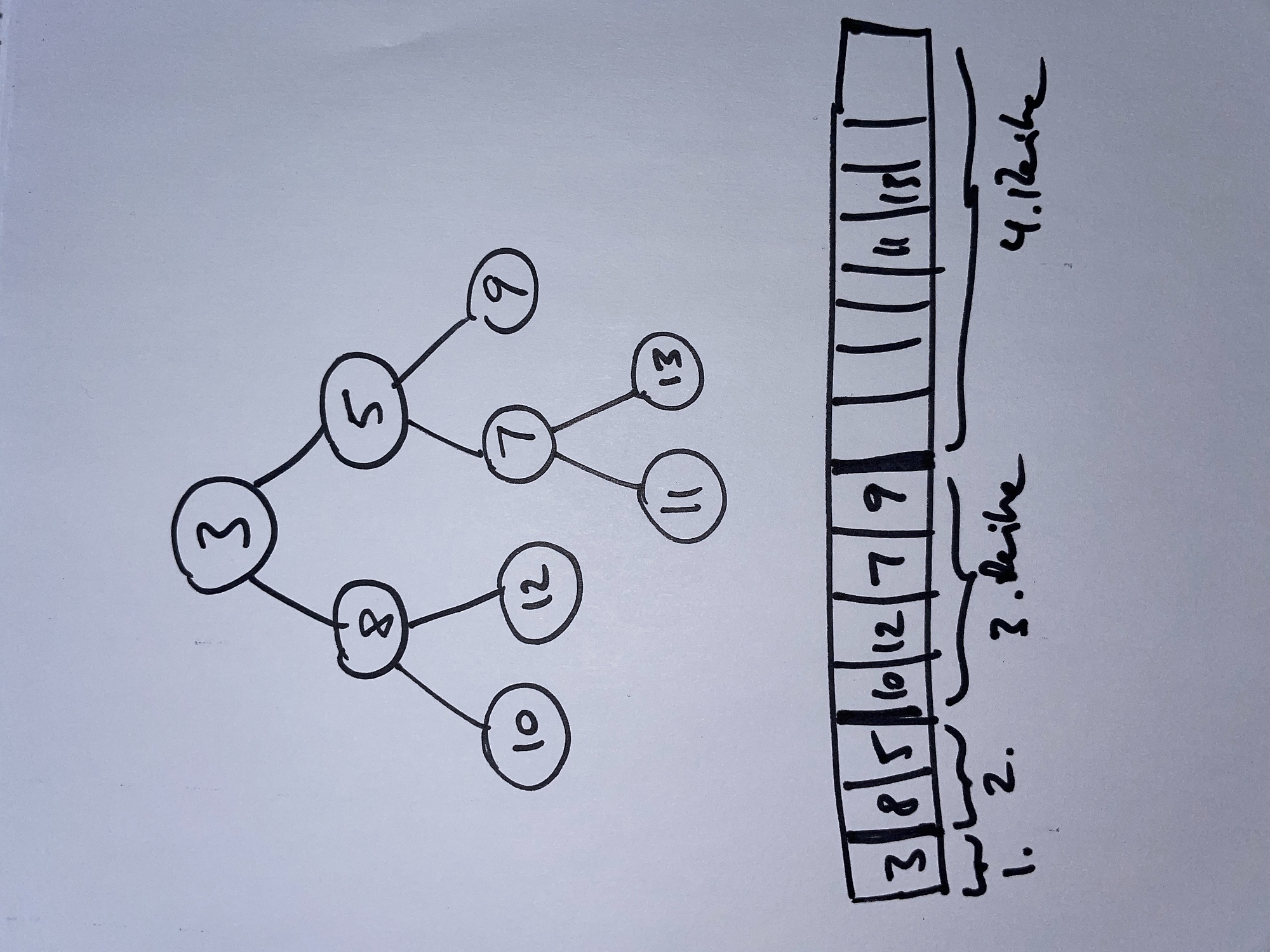 |
| Abbildung 3: Die Datenstruktur Min-Heap und ihre Array-Repräsentation |
Wie durchwandert das Go-Programm die tief verschachtelte Dateistruktur, um die Bytes jeder einzelnen Datei zu zählen und eine kurze Liste der dicksten Brummer auszugeben? Für die größten 10 aus einer großen Zahl von Dateien, die schnell bis in die Millionen gehen kann, verbietet sich die einfache Lösung, alle Einträge in einen Array abzulegen, dessen Einträge absteigend nach Dateigröße zu sortieren und anschließend die ersten 10 Einträge auszugeben. Selbst ein effektiver Sortieralgorithmus braucht für eine Million Einträge seine Zeit, ganz zu schweigen vom RAM, das so ein riesiger Array verschwendet, und von dem am Ende nur 10 Einträge interessieren.
Eine effiziente Datenstruktur für derartige Probleme ist der sogenannte Min-Heap, ein Binärbaum, dessen Knoten immer der Vorschrift genügen, dass die Knoten unterhalb eines bestimmten Knotens immer größere Werte aufweisen als der Knoten selbst. So steht in Abbildung 3 oben an der Wurzel des Baumes der Knoten mit dem Wert 3, der kleiner als alle anderen Werte des Baum ist. Die Vorschrift gilt übrigens nur für Knoten, die direkt oder indirekt miteinander verbunden sind, so ist es durchaus zulässig, dass zum Beispiel in Abbildung 3 in der zweiten Reihe von oben der Wert 8 steht, aber in der dritten Reihe des rechten Teilbaums der Wert 7.
Programme stellen den Baum als simples Array dar, das wie in Abbildung 3 gezeigt, für die Reihen des Baumes jeweils ein, zwei, vier, acht und so weiter lange Bereiche anlegt, die nahtlos aneinander grenzen. Es ist nun relativ einfach, den kleinsten Eintrag im Baum zu finden und zu entfernen, denn er befindet sich stets oben an der Wurzel. Den Baum anschließend so umzusortieren, dass ein anderer Knoten den Platz des entfernten einnimmt und die anderen Knoten aufrücken, auf dass der Baum wieder den alten Knotenregeln genügt, ist ebenfalls relativ einfach mit einem standartisierten Algorithmus zu bewerkstelligen.
Und damit ist die Datenstruktur ideal für eine aktiv aktualisierte Liste der N größten bislang gefundenen Dateien: Enthält der Baum anfangs noch weniger als N Knoten, wandern alle neu gefundenen Dateien ungeprüft hinein. Wächst der Baum beim Einfügen einer neuen Datei hingegen auf N+1 Knoten an, muss er wieder auf N Knoten schrumpfen, und das geht am besten, indem der Algorithmus den Wurzelknoten mit der kleinsten Datei entfernt und die restlichen Knoten nachrücken lässt.
Abbildung 3 zeigt die Ausgabe des Testprogramms in Listing 1, das erst den Heap mit den Pfaden zu acht Dateien und deren Größe in Bytes vollschreibt, aber die Maximalgröße des Heaps immer auf sechs Einträge begrenzt hält. Heraus kommen am Ende die sechs größten Dateien aus dem Gesamtkorpus, und zwar sortiert nach absteigender Dateigröße. Die Einträge "abc" und "ghi" mit den Bytezählern 123 und 124 bleiben als kleinste Dateien erwartungsgemäß außen vor.
 |
| Abbildung 4: Ausgabe des Testprogramms für den Min-Heap |
01 package main
02 import (
03 "fmt"
04 )
05 func main() {
06 entries := []FsEntry{
07 {path: "abc", used: 123},
08 {path: "def", used: 456},
09 {path: "ghi", used: 124},
10 {path: "jkl", used: 457},
11 {path: "mno", used: 125},
12 {path: "pqr", used: 458},
13 {path: "stu", used: 126},
14 {path: "vwx", used: 999},
15 }
16 h := NewTopN(6)
17 for _, e := range entries {
18 h.Add(e)
19 }
20 h.Iterate(func(e FsEntry) {
21 fmt.Printf("%s %d\n", e.path, e.used)
22 })
23 }
Listing 1 legt dazu mit NewTopN() in Zeile 16 einen Min-Heap mit maximal sechs Knoten an, und die for-Schleife ab Zeile 17 wirft mit Add() jeweils den nächsten Eintrag aus dem Array-Slice entries auf den Min-Heap. Abschließend arbeitet sich Iterate() ab Zeile 20 durch die Gewinner-Einträge in der Datenstruktur, und zwar von der Datei mit dem höchsten Byte-Zähler bis zur kleinsten der Top Sechs.
Listing 2 zeigt die Implementierung der Top-N-Liste mittels eines Min-Heaps aus der Go-Standard-Bibliothek container/heap. Die Struktur vom Typ FsEntry ab Zeile 5 repräsentiert jeweils eine Datei mit dem Zugriffspfad und ihrer Größe in Bytes. Die Struktur topN ab Zeile 9 führt einen ganzen Array-Slice von FsEntry-Strukturen im Feld entries sowie die Maximalgröße des verwendeten Heaps im Feld n.
01 package main
02 import (
03 "container/heap"
04 )
05 type FsEntry struct {
06 path string
07 used int64
08 }
09 type topN struct {
10 entries []FsEntry
11 n int
12 }
13 func NewTopN(n int) *topN {
14 h := &topN{n: n, entries: []FsEntry{}}
15 heap.Init(h)
16 return h
17 }
18 func (h *topN) Add(fse FsEntry) {
19 heap.Push(h, fse)
20 if h.Len() > h.n {
21 heap.Pop(h)
22 }
23 }
24 func (h *topN) Iterate(cb func(fse FsEntry)) {
25 save := make([]FsEntry, len(h.entries))
26 copy(save, h.entries)
27 r := make([]FsEntry, h.Len())
28 for i := len(r) - 1; i >= 0; i-- {
29 r[i] = heap.Pop(h).(FsEntry)
30 }
31 for _, e := range r {
32 cb(e)
33 }
34 h.entries = save
35 }
36 func (h topN) Len() int {
37 return len(h.entries)
38 }
39 func (h topN) Less(i, j int) bool {
40 return h.entries[i].used < h.entries[j].used
41 }
42 func (h topN) Swap(i, j int) {
43 h.entries[i], h.entries[j] = h.entries[j], h.entries[i]
44 }
45 func (h *topN) Push(x interface{}) {
46 h.entries = append(h.entries, x.(FsEntry))
47 }
48 func (h *topN) Pop() interface{} {
49 old := h.entries
50 n := len(old)
51 x := old[n-1]
52 h.entries = old[:n-1]
53 return x
54 }
Der Konstruktor NewTopN ab Zeile 13 legt die in der Go-Objektorientierung übliche Instanz einer Struktur als Objekt an, ruft die Heap-Initialisierung heap.Init() aus der Standardbibliothek auf und gibt einen Pointer auf die Struktur an den Aufrufer zurück, der sie als Objektinstanz für zukünftige Aufrufe nutzt.
Die Funktion Add() ab Zeile 18 nimmt eine Variable vom Typ FsEntry mit dem Pfad zu einer Datei und deren Größe entgegegen und wirft sie auf den Min-Heap. Dazu nutzt sie die Funktion heap.Push() aus der Standardbibliothek container/heap, prüft aber anschließend mit Len(), ob diese Aktion den Heap nicht über die zulässige Länge hinaus vergrößert hat. Ist dies der Fall, korrigiert heap.Pop() in Zeile 21 das Malheur, indem es den Eintrag an der Wurzel des Baums, also die kleinste Datei, entfernt und verwirft.
Um die Einträge im Heap zu durchwandern, baut Iterate() ab Zeile 24 mit sukzessiven Aufrufen von heap.Pop() den Heap ab, angefangen vom kleinsten Element an der Wurzel des Baums, und dann weiter mit dem jeweils nächstgrößeren. Da die Ausgabe allerdings umgekehrt erfolgen soll, also beginnend mit der größten Datei und endend mit der kleinsten, legt die for-Schleife ab Zeile 28 die hereinkommenden Werte rückwärts in einem neu angelegten Array r ab, den die for-Schleife ab Zeile 31 anschließend vorwärts durchschreitet und für jeden gefundenen Knoten die vom Aufrufer hereingereichte Callback-Funktion cb aufruft. Dort kann dann der Aufrufer definieren, was mit dem Ergebnis geschieht. Im Fall des Testprogramms gibt es die Kombination aus Pfad und verbrauchtem Speicherplatz einfach aus. Da heap.Pop() den Heap sukzessive abbaut und damit zerstört, sichert Iterate() die interne Datenstruktur vorab, um sie am Ende wieder herzustellen. Dazu kopiert sie den Array-Slice entries mittels der Go-internen Funktion copy() in einen weiteren Array und restauriert das Heap-Objekt abschließend damit. So bleibt es auch für später folgende Aufrufe intakt.
Aufmerksame Leser wundern sich nun, wie es denn kommt, dass die benutzerdefinierte Struktur vom Typ topN auf einmal in Aufrufen wie heap.Init() als Parameter auftaucht, ohne dass Go mit seinem strengen Typsystem sich über den Fremdkörper beschwert. Wie kann es sein, dass die Standard-Library container/heap weiß, dass sich der im Heap verwendete Array-Slice im Feld entries befindet, oder wie sich die Elemente vom Typ FsEntry absteigend nach Dateigröße sortieren lassen?
Des Rätsels Lösung ist, dass der Typ topN ab Zeile 36 in Listing 2 die Funktionen Len(), Push(), Pop(), Less() und Swap() definiert, und damit dem Interface von container/heap genügt. So kann die Standard-Library die Länge des Heaps bestimmen, Elemente ans Ende des internen Arrays einhängen, oder dessen letztes Element entfernen. Less() ab Zeile 39 bestimmt, welches von zwei Elemente das größere ist, und Swap(), wie der Algorithmus zur Wartung des Heaps zwei Elemente vertauscht. Mit diesem Werkzeugkasten kann eine Funktion wie heap.Pop() (nicht zu verwechseln mit Pop() aus Zeile 48 von Listing 1) dann später den Knoten an der Wurzel des Baumes entfernen, zurückgeben, und den Baum wieder in Form bringen. Programmierte Magie!
Mit diesem Rüstzeug kann nun Listing 3 daran gehen, das vom User auf der Kommandozeile angegebene Verzeichnis rekursiv zu durchforsten, die verbrauchte Anzahl der Bytes der in den Untiefen der Hierarchie liegenden Dateien zu einer Gesamtsumme aufzuaddieren und für jedes direkte Unterverzeichnis einen Min-Heap mit den fünf gierigsten Speicherfressern anzulegen. Dazu steigt die Standardfunktion Walk aus Gos filepath-Library in einer Depth-First-Suche (Abbildung 5) hinab in die Verzeichnisstruktur der Festplatte und ruft für jeden gefundenen Eintrag den ab Zeile 14 definierten Callback auf. Aufgestöberte Unterverzeichnisse ignoriert dieser ab Zeile 18 und nur bei Dateien (oder Links) bestimmt der Code ab Zeile 21 deren relativen Pfad zum Einstiegsverzeichnis sowie deren oberstes Unterverzeichnis (topDir). Unter diesem Schlüssel kreiert es jeweils einen Eintrag in der Hash-Map duTotal, der die bislang darunter aufsummierten Bytes und einen neuen Min-Hash zum Verfolgen der dicksten Dateien speichert.
Ganz genau stimmt diese einfache Version des Byte-Zählers übrigens nicht: Zusätzliche Hardlinks, also weitere Inodes, die auf bereits bestehende Dateien zeigen, zählt er doppelt. Mit etwas Aufwand lässt sich dies allerdings korrigieren, der Erbsenzähler muss dazu eine riesige Tabelle anlegen und zu jeder bereits gesehenen Datei die Festplattennummer und deren Inode ablegen. Trifft er anschließend auf einen Eintrag, der dieselben Werte hat, handelt es sich um einen Hardlink, der nur einmal gezählt werden sollte.
 |
| Abbildung 5: Die Depth-First-Methode der Baumdurchquerung |
Die Aufruf von Add() des Min-Heaps in Zeile 35 registriert den aktuell gefundenen Eintrag, der nur dann nicht sofort verworfen wird, falls er aufgrund seiner Größe noch in die Top-Fünf passt. Insgesamt erhält der Aufrufer von duDir() zwei Resultate: Die Gesamtzahl der unter dem analysierten Verzeichnis verbratenen Bytes sowie eine Hashtabelle duTotal, die die obersten Verzeichnisse der Hierarchie ihren Min-Heaps zuweist. Der Parameter steht als Pointer in der Aufrufliste steht und dient damit ebenfalls als Rückgabewert.
01 package main
02 import (
03 "os"
04 "path/filepath"
05 "strings"
06 )
07 type duEntry struct {
08 h *topN
09 used int64
10 }
11 func duDir(dir string, duTotal *map[string]duEntry) (int64, error) {
12 total := int64(0)
13 err := filepath.Walk(dir,
14 func(fpath string, info os.FileInfo, err error) error {
15 if err != nil {
16 return err
17 }
18 if info.IsDir() {
19 return nil
20 }
21 fpath, _ = filepath.Rel(dir, fpath)
22 parts := strings.Split(fpath, "/")
23 fileName := strings.TrimPrefix(fpath, parts[0]+"/")
24 topPath := parts[0]
25 // find or create new path mapping
26 var due duEntry
27 var ok bool
28 if due, ok = (*duTotal)[topPath]; !ok {
29 due = duEntry{}
30 due.h = NewTopN(5)
31 }
32 // add file to dir's heap
33 fse := FsEntry{path: fileName, used: info.Size()}
34 fse.used = info.Size()
35 due.h.Add(fse)
36 due.used += info.Size()
37 (*duTotal)[topPath] = due
38 total += info.Size()
39 return nil
40 })
41 return total, err
42 }
Das Hauptprogramm in Listing 4 prüft anfangs, ob der User auf der Kommandozeile auch ein Verzeichnis zur Analyse mitgegeben hat, und beschwert sich andernfalls. Mit einer anfangs leeren Map duTotal, die den obersten Verzeichnissen jeweils Zähler vom Typ duEntry zuweist, ruft es dann duDir() aus Listing 3 auf, das die Festplatte durchstöbert und die Ergebnisse hochgibt. Liegen anschließend mehr als 10 Top-Verzeichnisse vor, filtert der Min-Hash ab Zeile 19 die dicksten zehn heraus und die Sortierfunktion ab Zeile 30 bringt sie in alphabetische Reihenfolge, bevor der Aufruf von ui() in Zeile 33 das Ganze an die Terminal-UI zur Anzeige weiterreicht.
01 package main
02 import (
03 "fmt"
04 "os"
05 "sort"
06 "strings"
07 )
08 func main() {
09 if len(os.Args) != 2 {
10 fmt.Printf("usage: %s dir\n", os.Args[0])
11 os.Exit(1)
12 }
13 topDir := os.Args[1]
14 duTotal := map[string]duEntry{}
15 bytes, err := duDir(topDir, &duTotal)
16 if err != nil {
17 panic(err)
18 }
19 topn := NewTopN(10)
20 for dir, due := range duTotal {
21 if strings.Count(dir, "/") > 1 {
22 continue
23 }
24 topn.Add(FsEntry{path: dir, used: due.used})
25 }
26 lines := []FsEntry{}
27 topn.Iterate(func(e FsEntry) {
28 lines = append(lines, e)
29 })
30 sort.Slice(lines, func(i, j int) bool {
31 return lines[i].path < lines[j].path
32 })
33 ui(topDir, bytes, lines, duTotal)
34 }
Zur grafischen Anzeige der bislang gesammelten Daten schreitet dann Listing 5 mit dem schon im letzten Snapshot verwendeten Framework tview zur Darstellung im Grafik-Modus des Terminals.
01 package main
02 import (
03 "fmt"
04 "github.com/gdamore/tcell/v2"
05 "github.com/rivo/tview"
06 "golang.org/x/text/language"
07 "golang.org/x/text/message"
08 )
09 func ui(rootDir string, bytes int64, dirs []FsEntry, duTotal map[string]duEntry) {
10 root := tview.NewTreeNode(fmt.Sprintf("%s %s", rootDir, commify(bytes))).
11 SetColor(tcell.ColorRed)
12 tree := tview.NewTreeView().
13 SetRoot(root).
14 SetCurrentNode(root)
15 for _, dir := range dirs {
16 node := tview.NewTreeNode(fmt.Sprintf("%s %s", dir.path, commify(dir.used))).
17 SetExpanded(false).
18 SetSelectable(false)
19 // new dir
20 root.AddChild(node)
21 node.SetSelectable(true)
22 node.SetColor(tcell.ColorGreen)
23 dut, ok := duTotal[dir.path]
24 if !ok {
25 panic(fmt.Sprintf("Can't find %s", dir.path))
26 }
27 // add sub-menu
28 h := dut.h
29 h.Iterate(func(fse FsEntry) {
30 line := fmt.Sprintf("%s %s", fse.path, commify(fse.used))
31 n := tview.NewTreeNode(line).
32 SetExpanded(false).
33 SetSelectable(false)
34 node.AddChild(n)
35 })
36 }
37 tree.SetSelectedFunc(func(node *tview.TreeNode) {
38 node.SetExpanded(!node.IsExpanded())
39 })
40 err := tview.NewApplication().SetRoot(tree, true).EnableMouse(true).Run()
41 if err != nil {
42 panic(err)
43 }
44 }
45 func commify(i int64) string {
46 p := message.NewPrinter(language.English)
47 return p.Sprintf("%d", i)
48 }
Der oberste Eintrag im dargestellten Baum ist das dem Programm mitgegebene Startverzeichnis, zusammen mit der Gesamtzahl der dort verbrauchten Bytes. Zeile 10 definiert den Eintrag und färbt ihn rot. Der Baum selbst liegt in der Variablen tree ab Zeile 12, der erst den Root-Knoten einhängt und weiter unten in der for-Schleife ab Zeile 15 die Top-Verzeichnisse, die darunter liegen.
Jeder dieser Einträge kommt mit AddChild() als Ast im Baum zu liegen und wird mit SetSelectable() auswählbar gemacht. Der User drückt hierzu entweder die Enter-Taste oder klickt mit der Maus darauf. Was auf dieses Ereignis hin passiert, definiert der Aufruf der Funktion SetSelectedFunc() weiter unten in Zeile 37, deren Callback das Attribut SetExpanded() entweder auf wahr oder falsch setzt, je nachdem, ob der Eintrag schon aufgefächert vorliegt oder nicht.
Um die dargestellten Zahlenwerte besser lesbar zu machen, fügt die ab Zeile 45 definierte Funktion commify() Kommas in die Integerwerte ein, so wird aus 123456789 das einfacher lesbare 123,456,789. Dies passiert mittels der Standard-Libraries golang.org/x/text/language und -message, deren Funktion NewPrinter() diese im englischsprachigen Raum übliche Darstellung vornimmt.
Zeile 40 fügt das vorher definierte Tree-Objekt in das von tview kontrollierte Terminalfenster ein, schaltet das Terminal in der Grafikmodus und Run() startet die Event-Schleife, die User-Eingaben abfängt und die Anzeige entsprechend eingehender Ereignisse auffrischt. Am Ende unterbricht die Tastenkombination ctrl-c den Reigen, schaltet das Terminal zurück in den normalen Textmodus und lässt die Shell wieder ran.
Folgender Dreisatz erzeugt aus den vier Sourcen das Binary duview:
$ go mod init duview
$ go mod tidy
$ go build duview.go space.go ui.go heap.gound mit einem zu analysierenden Verzeichnis aufgerufen kommt nach einigen Sekunden, abhängig vom Füllstatus, Größe und Performance der Festplatte, das Ergebnis auf den Schirm. Auf geht's beim Schlussverkauf, alles Alte muss raus!
Listings zu diesem Artikel: http://www.linux-magazin.de/static/listings/magazin/2023/09/snapshot/
 |
Michael Schilliarbeitet als Software-Engineer in der San Francisco Bay Area in Kalifornien. In seiner seit 1997 laufenden Kolumne forscht er jeden Monat nach praktischen Anwendungen verschiedener Programmiersprachen. Unter mschilli@perlmeister.com beantwortet er gerne Ihre Fragen. |
Hey! The above document had some coding errors, which are explained below:
Unknown directive: =desc