Streamingdienste wie Spotify oder Apple Music dominieren die Musikindustrie. Ihre umfangreichen Kataloge decken mittlerweile das gesamte Spektrum konsumierbarer Musik ab und dank künstlicher Intelligenz führen sie User an immer neue Songs heran, die diese mit hoher Wahrscheinlichkeit begeistert abspielen. Dagegen haben traditionelle Tonträger keine Chance mehr, und verstauben in den Regalen. Vorbei ist durch diese Entwicklung aber auch der anonyme Musikkonsum, denn Streamingdienste führen genau darüber Buch, wer wann und wie lang welche Musik laufen ließ.
| |
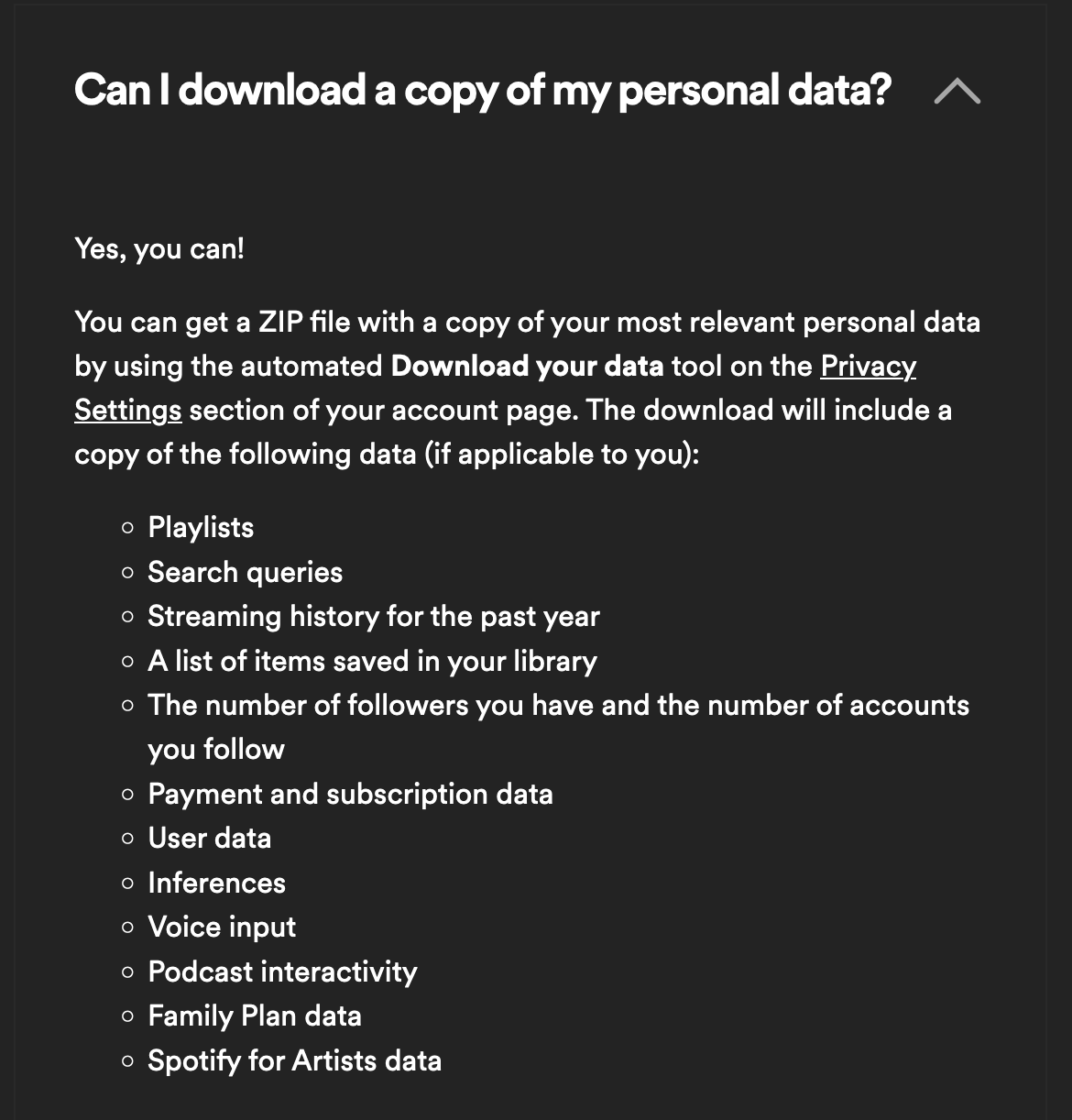
| Abbildung 1: Spotify gestattet es seinen Usern, die über sie gesammelten Daten einzusehen. |
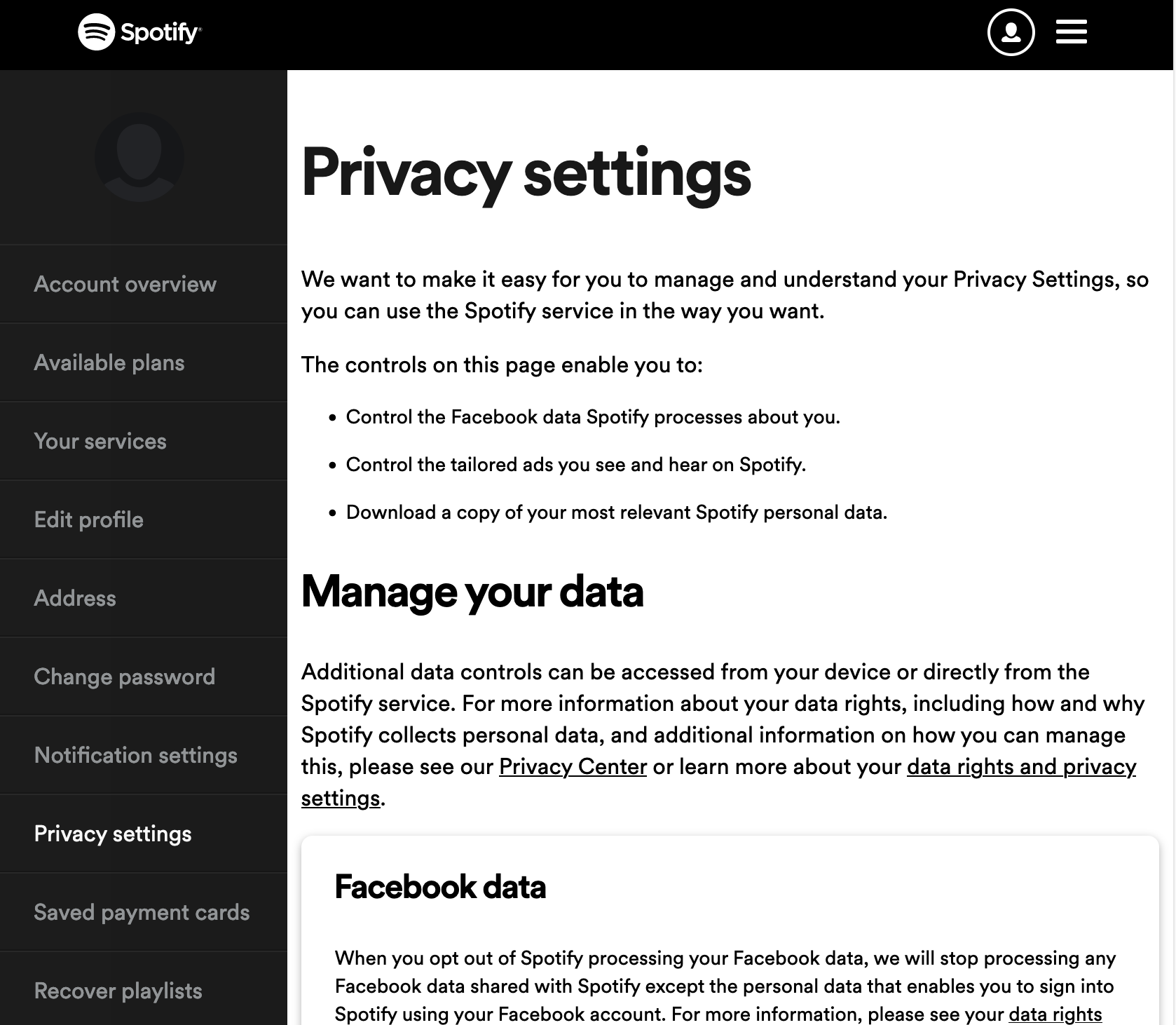 |
| Abbildung 2: Unter Account->Privacy Settings können User ihre Daten zum Download ordern. |
Diese gesammelten Daten rückt Spotify auf Anfrage sogar heraus. Wer geduldig herumstöbert, findet auf Spotifys Website die richtigen Knöpfe, um eine Kopie dieser Akten anzufordern (Abbildungen 1 und 2). Mit der Antwort lässt sich Spotify Zeit. Vom Zeitpunkt der Anfrage dauert es etwa eine Woche, bis anscheinend ein ärmelschonertragender Archivar die Daten in Leitz-Ordnern aus dem Spotify-Keller holt, komprimiert und als Zip-Archiv auf der Website zur Abholung bereitstellt. Der mittels einer Email benachrichtigte User darf die Daten dann während eines Zeitraums von zwei Wochen herunterladen und darin herumstöbern.
 |
| Abbildung 3: Nach knapp einer Woche standen die Daten zum Download bereit. |
In der Zip-Datei mit den heruntergeladenen Daten findet sich eine Json-Datei namens StreamingHistory0.json, die die Metadaten aller abgespielten Streams in ihrer historischen Reihenfolge enthält (Abbildung 4). Neben Song und Künstler listen die Einträge auch noch das Startdatum mit Uhrzeit sowie die Spieldauer auf. Letztere ist besonders interessant, denn wenn der User den Stream nach wenigen Sekunden abbricht und auf den nächsten Song vorspult, hat sich das Stück wahrscheinlich irrtümlich auf die Playlist verirrt und den User genervt, wird sich also beim Zusammenstellen von Musikvorschlägen höchstwahrscheinlich als Ente entpuppen.
 |
| Abbildung 4: Json-Daten der Streaming-History |
Als leichte Fingerübung zeigt Listing 1 ein Go-Programm, das sich durch die Json-Daten schlängelt und eine Hitparade der meistgespielten Songs erstellt. Die Ausgabe der Top Drei enthüllt meine Lieblingssongs (natürlich abzüglich derer, die wegen Peinlichkeit von der Veröffentlichung ausgenommen wurden):
Sparks/When Do I Get to Sing "My Way" - 2019 - Remaster (19x)
Falco/The Sound of Musik (16x)
Linkin Park/With You (14x)Dazu öffnet Listing 1 in Zeile 22 die Json-Datei und erhält ein Objekt in der Variablen content zurück, das das Reader-Interface beherrscht. Dieses gibt Zeile 27 an die Funktion Unmarshal aus dem json-Paket in Gos Standard-Fundus weiter, mitsamt einem Pointer auf eine Struktur vom Typ stream, die vorher ab Zeile 10 definiert wurde. Go insistiert ja bekanntlich auf strenger Typprüfung, und damit der Json-Parser aus den Spotify-Daten eine Go-interne Datenstruktur machen kann, muss deren Format bekannt sein und natürlich auch mit dem der tatsächlichen Json-Daten übereinstimmen. Das von Spotify geliefert Json besteht, wie aus Abbildung 4 ersichtlich, aus einem Array, dessen Elemente jeweils einem gestreamten Titel entsprechen. In den Feldern ArtistName und TrackName enthalten sie Interpret und Songtitel als Strings, sowie in MsPlayed die Spieldauer in Millisekunden und in EndTime das Datum und die Uhrzeit am Ende des Abspiels.
Die Felder der Struktur stream im Listing beginnen jeweils mit einem Großbuchstaben, damit andere Pakete später auch auf sie zugreifen dürfen. Dadurch sind die Namen jedoch nicht identisch mit den Variablennamen im Json-Format, die jeweils mit einem Kleinbuchstaben beginnen. Das ist aber kein Beinbruch, denn Go erlaubt es, einer Struktur mit der Markierung `json:` einen eventuell vom Feldnamen abweichenden Namen anzugeben. So legt zum Beispiel ArtistName string `json:artistName` in Zeile 12 fest, dass der Interpret im Feld ArtistName vom Typ String in der Go-Struktur zu liegen kommt, und dass der im hereinkommenden Json dafür verwendete Name artistName ist. Das genügt, damit sich json.Unmarshal() in Zeile 27 durch alle Einträge der Json-Datei wühlt, denn der Funktion wurde ein noch leerer Array dieser stream-Einträge in data als Pointer übergeben, und durch Reflexion findet die Funktion heraus, durch welche Json-Strukturen sie sich durcharbeiten muss.
Listing 1 zählt in der Map bySong, die in Zeile 20 definiert ist, wieviel mal ein Song in der Streaming-Historie vorkommt. Dazu verwendet sie den String des Songnamens als Schlüssel und zählt den dahinterliegenden 64-Bit-Integer bei jedem gefundenen Abspiel-Event um Eins hoch. Am Ende muss es dann die Map nach dem höchsten Integer-Wert absteigend sortieren, um die Top Drei auszugeben.
In einer Skriptsprache wäre dies ein Klacks, aber Go bietet Typsicherheit und deswegen wandelt Listing 1 die Map-Einträge in ein Array-Slice von kv-Strukturen (für key/value) um, deren Typ es ab Zeile 37 definiert. Die For-Schleife ab Zeile 44 muss dann durch die Einträge der Map rattern, und jeden gefundenen Eintrag als kv-Struct an den Array-Slice kvs anhängen. Diesen kann dann Gos Standardfunktion sort.Slice() sortieren, weil der Callback in Zeile 49 ihr mitteilt, dass sie die gewünschte Reihenfolge zweier Einträge im Slice an den Positionen i und j durch einen Integer-Größenvergleich der beiden Werte an diesen Positionen ermitteln kann.
Puh, ganz schön umständlich! Am Ende geht die For-Schleife ab Zeile 52 durch den sortierten Array, gibt die Top-Positionen aus und bricht nach dem dritten Wert ab.
01 package main
02
03 import (
04 "encoding/json"
05 "fmt"
06 "io/ioutil"
07 "sort"
08 )
09
10 type stream struct {
11 EndTime string `json:endTime`
12 ArtistName string `json:artistName`
13 MsPlayed int64 `json:msPlayed`
14 TrackName string `json:trackName`
15 }
16
17 const jsonFile = "MyData/StreamingHistory0.json"
18
19 func main() {
20 bySong := map[string]int64{}
21
22 content, err := ioutil.ReadFile(jsonFile)
23 if err != nil {
24 panic(err)
25 }
26 data := []stream{}
27 err = json.Unmarshal(content, &data)
28 if err != nil {
29 panic(err)
30 }
31
32 for _, song := range data {
33 title := fmt.Sprintf("%s/%s", song.ArtistName, song.TrackName)
34 bySong[title] += 1
35 }
36
37 type kv struct {
38 Key string
39 Value int64
40 }
41
42 kvs := []kv{}
43
44 for k, v := range bySong {
45 kvs = append(kvs, kv{k, v})
46 }
47
48 sort.Slice(kvs, func(i, j int) bool {
49 return kvs[i].Value > kvs[j].Value
50 })
51
52 for i := 0; i < 3; i++ {
53 fmt.Printf("%s (%dx)\n", kvs[i].Key, kvs[i].Value)
54 }
55 }
Go-Programme für's Parsen von Json-Daten und deren statistische Auswertung gehen also nur mühsam von der Hand. Gos Typsicherheit erfordert hier unverhältnismäßig viel Boilerplate-Code, den Skriptsprachen elegant vermeiden.
Der Klassiker unter den Datenwurstlern, die Sprache R, geht da unbeschwerter vor und spart so manchen Arbeitsschritt. Wer R noch nicht auf dem Rechner hat, installiert es zum Beispiel unter Ubuntu einfach mit
sudo apt install r-basenach. Listing 2 zeigt eine einfache Anwendung, die die Streaming-History von Spotify durchforstet, ein Histogramm über die Anspiellängen der abgespielten Songs erstellt, und dieses auch noch formschön grafisch darstellt (Abbildung 5). Das Diagramm illustriert, dass viele Songs nach weniger als 15 Sekunden (15000 Millisekunden) einfach abgebrochen werden, sich Spotifys Vorschlagsalgorithmus also geirrt und der Hörer genervt auf den nächsten Song geschaltet hat. Ab etwa einer Minute Anspielzeit (also nach 60.000 Millisekunden) zeigt sich eine fast Gauss-artige Glockenkurve, deren Scheitel bei 220 Sekunden liegt. Die meisten Songs sind heutzutage also etwa dreieinhalb Minuten lang, die Mehrzahl liegt zwischen zwei und fünf Minuten.
01 #!/usr/bin/env Rscript
02 library("jsonlite")
03
04 jdata <- fromJSON("MyData/StreamingHistory0.json", simplifyDataFrame = TRUE)
05 jdata <- jdata[jdata$msPlayed < 300000, ]
06
07 attach(jdata)
08 png(filename="hist.png")
09 hist(msPlayed, main="Milliseconds Played")
10 detach(jdata)
Damit Listing 2 sich von der Kommandozeile aufrufen lässt, sucht die Shebang-Anweisung in der ersten Zeile das Programm Rscript in den Suchpfaden der Shell und ruft den dahinter steckenden R-Interpreter auf mit dem Programmcode aus dem Listing auf.
Zum eleganten Einlesen der Json-Daten nutzt Listing 2 das Paket jsonlite, das der Admin vorab installieren muss. Nach dem Öffnen einer R-Session (einfach "R" auf der Kommandozeile eingeben) lädt der Befehl
> install.packages("jsonlite")die C++-Sourcen des Pakets aus dem CRAN-Netzwerk, kompiliert diese lokal und bindet die Library ins R-Universum ein. Anschließend darf jedes R-Skript mit library("jsonlite") die neue Library einbinden und Funktionen daraus aufrufen.
Zeile 4 liest mit der aus jsonlite exportierten Funktion fromJSON die Json-Daten aus der Streaming-History und legt sie als sogenannten Dataframe der Variablen jdata ab. Dieser Standard-Typ in R ist eine Art Datenbanktabelle mit reihenweise Vektorwerten, die sich jeweils über mehrere Spaltenwerte erstrecken. Dabei dürfen die Spalten numerische Werte annehmen, oder Strings, oder auch sogenannte "Factors", was in R Variablen mit einer bestimmten Zahl möglicher Werte sind, wie zum Beispiel small, medium und large.
Listing 2 muss die maximal erfasste Anspiellänge auf 5 Minuten begrenzen, da meine Streaming-History auch Hörspiele mit anderthalb Stunden Länge enthielt, die die Statistik bis zur Unkenntlichkeit verzerrten. Das Filtern erledigt die sogenannte Recoding-Anweisung in Zeile 5, die mit der Bedingung jdata$msPlayed < 300000 alle Stücke über 300 Sekunden Spieldauer aus dem Dateframe jdata ausfiltert und das Ergebnis wiederum der Variablen jdata zuweist.
Das Recoding passiert sowohl auf Reihen- also auch Spaltenniveau: in den eckigen Klammern in Zeile 5 stehen, durch ein Komma getrennt, die Bedingungen. Die erste wendet der Filter auf jede Reihe an, die zweite auf jede Spalte. So kommt hintenraus ein Dataframe, der unter Umständen sowohl weniger Zeilen als auch Spalten führt. Im vorliegenden Fall gilt es aber nur, Reihen zu entfernen, und keine Spalten, und deshalb bleibt der zweite Teil der Bedingung in eckigen Klammern nach dem Komma leer.
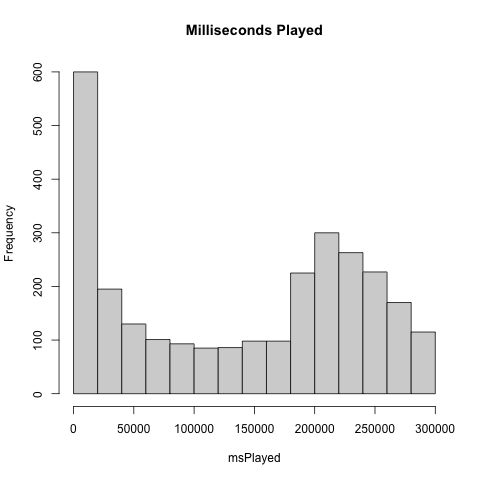 |
| Abbildung 5: Statistische Anspieldauer in Millisekunden |
Das sehr kompakte Listing muss anschließend nur noch ein Histogramm über die msPlayed-Einträge im Dataframe jdata erstellen und die Zählerwerte für Spieldauern in einer Balkengrafik aufbereiten. Das macht die eingebaute R-Funktion hist() in Zeile 9, nachdem Zeile 7 den Dataframe jdata als Bezugspunkt eingestellt und Zeile 8 etwaige PNG-Ausgabedateien auf hist.png gesetzt hat. Dies sorgt dafür, dass R am Ende des Skripts die PNG-Datei mit der Balkengrafik in Abbildung 5 unter diesem Namen anlegt.
Erlauben die Daten in der Streaming-Historie auch Rückschlüsse auf eine Vorliebe für bestimmte Musik, abhängig von der Tageszeit? Listing 3 liest wieder die Json-Daten ein, extrahiert aus dem endTime-Datumsstempel jedes Streaming-Ereignisses die Stunde der Abspielendzeit als numerischen Wert, und bestimmt anschließend, welcher Interpret innerhalb dieses Zeitfensters über alle Tage gemittelt am häufigsten gespielt wurde.
 |
| Abbildung 6: Original-Dataframe aus den Json-Daten |
Abbildung 6 zeigt die Original-Json-Daten im Dataframe, mit allen in der Json-Datei definierten Feldern. Zeile 7 in Listing 3 verwirft alle Songs, die nicht mindestens eine Minute lang gelaufen sind, um versehentliche Irrtümer nicht in die Statistik einfließen zu lassen. Nun gilt es, aus dem Spotify-Zeitstempel die Tagesstunde herauszufieseln, und zwar nach dem Anpassen der Zeitzone, da Spotify die Zeiten als UTC (also GMT) notiert, ich aber der Musik in der Zeitzone "Pacific Time" an der Westküste der USA lausche. So liest die Funktion as.POSIXct() den Wert als UTC aus dem Json, aber der Formatierer format in Zeile 10 gibt ihn für die Zone America/Los_Angeles aus. Anschließend liegt der mit "%H" ermittelte Stundenwert als String vor, aber um die Einträge später zu sortieren, braucht R numerische Werte, und as.numeric() macht eine Zahl daraus.
 |
| Abbildung 7: Gefilterter Dataframe mit Stundenspalte |
Nun liegt der Dataframe wie in Abbildung 7 gezeigt in der Variablen jdata. Zeile 11 macht mit subset() aus den vollständigen Daten anschließend einen Dataframe mit nur zwei Spalten, dem Interpreten und der Abspielstunde.
Die in R eingebaute Funktion aggregate() fasst nun in Zeile 13 alle Zeilen für einen Interpreten mit dem gleichen Stundenwert zusammen. FUN=length legt dabei fest, dass in der zusätzlichen Aggregationsspalte die Länge, also die Anzahl der Interpret/Stunden-Tupel zu liegen kommt.
 |
| Abbildung 8: Aggregierte Zähler pro Stunde |
Abbildung 8 zeigt einen Ausschnitt dieses Zwischenergebnisses. Danach wurde die Gruppe "ZZ-Top" zur Stunde 19 genau einmal gespielt, wärend sich ganze 11 Einträge zur Stunde 20 mit der Gruppe "Linkin Park" fanden. Um aus dieser Darstellung jetzt nur die Spitzenreiter herauszufiltern (also zum Beispiel zur Stunde 20 die Gruppe "Linkin Park") bieten sich mehrere Verfahren an, aber eines, das mit Rs Standardfunktionen auskommt, geht so: Der Dataframe wird nach Stunde (aufsteigend) und Anzahl der Ereignisse (absteigend) sortiert, und dann mittels Deduplikation jeweils nur der erste Eintrag pro Stundenwert beibehalten, der Rest verworfen.
Zeile 15 sortiert den Dataframe agg entsprechend der in den eckigen Klammern angegebenen Funktion order(): ihr erster Parameter ist der (positive) Feldname für den Stundenwert, der zweite der (negative) für den von R x genannten Zähler der length-Funktion, der die Anzahl der Ergebnisse enthält.
Zeile 16 führt eine Recode-Anweisung auf den nun winners genannten Dataframe aus, und gibt mit !duplicated(winners[2]) an, dass das zweite Feld (also der Stundenwert, R-Arrays fangen immer mit Index 1 an, nicht mit 0) immer nur einmal im Ergebnis vorliegen darf. Folglich behält die Funktion immer nur den vorher nach vorne sortierten höchsten Ergebniswert für einen Stundenwert mit dem zugehörigen Interpreten, und verwirft alle anderen.
01 #!/usr/bin/env Rscript
02 library("jsonlite")
03
04 jdata <- fromJSON("MyData/StreamingHistory0.json", simplifyDataFrame = TRUE)
05
06 # only enjoyed songs
07 jdata <- jdata[jdata$msPlayed > 60000, ]
08
09 d <- as.POSIXct(jdata$endTime, tz = "UTC")
10 jdata$hour <- as.numeric(format(d, tz="America/Los_Angeles", "%H"))
11 songs <- subset(jdata, , select=c(hour, artistName))
12
13 agg <- aggregate(songs$hour, by=list(artistName=songs$artistName, hour=songs$hour), FUN=length)
14
15 winners <- agg[order(agg$hour, -agg$x),]
16 winners <- winners[!duplicated(winners[2]),]
17 winners
Und fertig ist die Liste mit den beliebtesten Gruppen, abhängig von der Tageszeit im Büro der Perlmeister-Studios! Abbildung 9 zeigt die Ausgabe des R-Programms hourly.r. Nach Mitternacht laufen in den heiligen Hallen der illustren Software-Bude nachweislich entweder peinliche Oldies aus den 80ern (Rainbow) oder, wie ich mich vage zu erinnern glaube, einmal von 1 bis 4 Uhr nachts alle Titel der Gruppe "Sparks", von denen ich eine Netflix-Doku verschlungen hatte und daraufhin vier Stunden lang alle Songs abspielen ließ. Der nächste Arbeitstag war naturgemäß furchtbar, aber man lebt nur einmal.
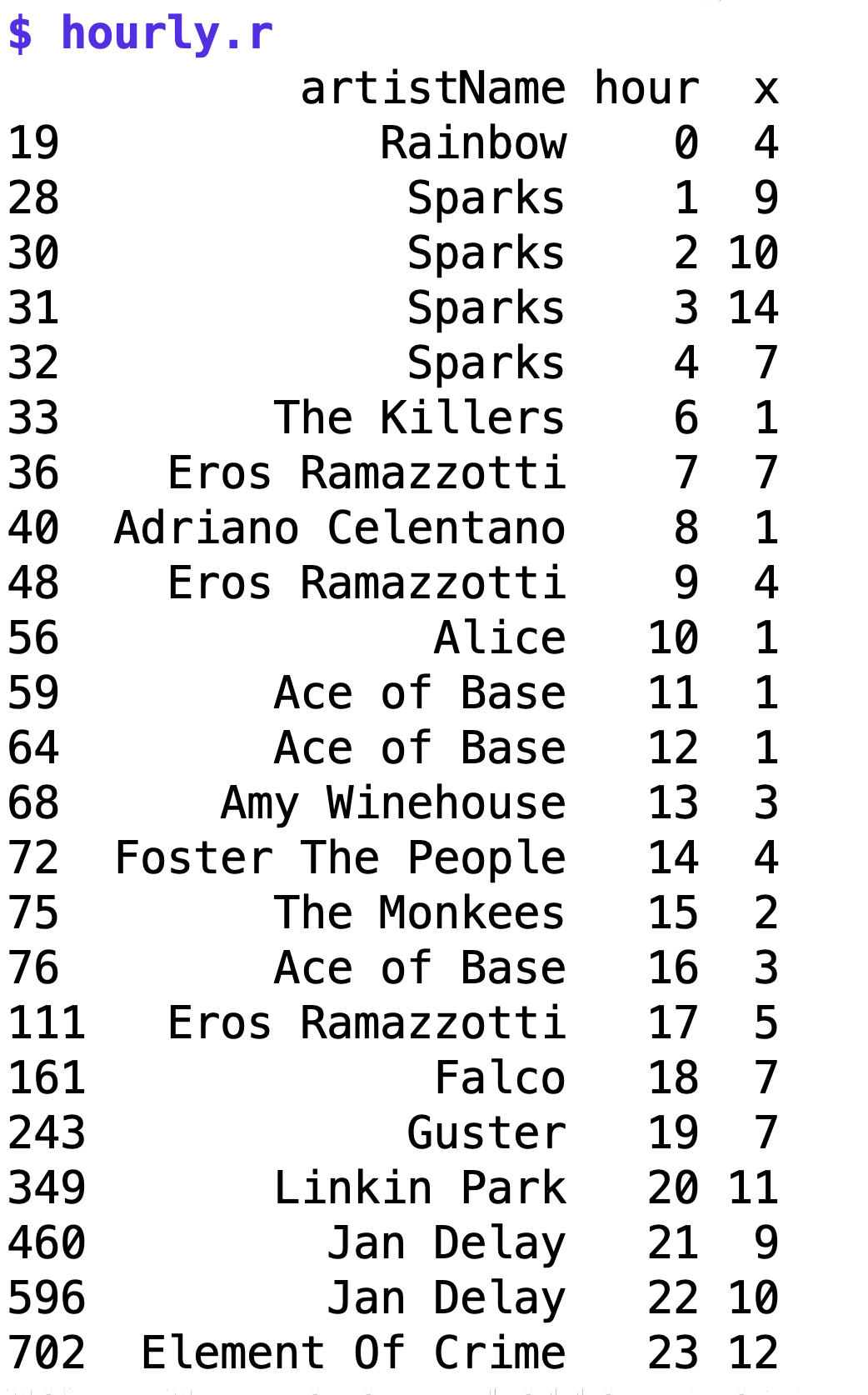 |
| Abbildung 9: Welche Interpreten laufen am häufigsten zu welcher Stunde? |
Erfahrungsgemäß kann es in R Tage dauern, bis der User die richtige Datenstruktur findet mitsamt den Methoden, die das Gewünschte dann in nur drei Zeilen implementieren. Grund dafür ist wohl das Alter der Sprache, die eine Art Anti-Python-Einstellung mitbringt, von wegen nur ein Weg führe zum Ziel, und die vielen vielen Pakete, die seit dem ursprünglichen Release der Sprache über Jahrzehnte hinweg unkoordiniert veröffentlicht wurden. Eine Google-Suche nach einem bestimmen Problem enthüllt so oft drei, vier verschiedene Wege zum Ziel. Das Schulungswerk von Kabacoff ([2]) erklärt ganz gut einige grundsätzliche Verfahren.
 |
| Abbildung 10: Das Zip-Archiv der Spotify-Daten enthält zahlreiche Json-Dateien |
Wer weiter in der Zip-Datei des Dossiers stöbert, findet noch das ein oder andere Datenjuwel (Abbildung 10). So zum Beispiel die Datei Inferences.json, die scheinbar von Spotify ermittelte Fakten über den User enthält, wohl um entsprechende Werbung zu schalten, auf die der User auch anspricht.
 |
| Abbildung 11: Spotify hält den Autor fälschlicherweise für einen Leichtbiertrinker. |
In meinem Fall nahm Spotify an, ich hätte eine Vorliebe für "Light Beer" (Abbildung 11), was natürlich und offensichtlich absurd und falsch ist, wie jedermann, der mich kennt, weiß und notfalls beeiden könnte! Bei eventuell aufpoppender Bud-Light Werbung läge hier die Erklärung.
Listings zu diesem Artikel: http://www.linux-magazin.de/static/listings/magazin/2023/01/snapshot/
"R in Action", 2nd edition, Robert I. Kabacoff, Manning 2015
 |
Michael Schilliarbeitet als Software-Engineer in der San Francisco Bay Area in Kalifornien. In seiner seit 1997 laufenden Kolumne forscht er jeden Monat nach praktischen Anwendungen verschiedener Programmiersprachen. Unter mschilli@perlmeister.com beantwortet er gerne Ihre Fragen. |
Hey! The above document had some coding errors, which are explained below:
Unknown directive: =desc